Friends don’t let friends disconnect their users every 24 hours.
Two of the most confused requirements in CMMC Level 2 / NIST SP 800-171 Rev. 2 are 3.1.11 “User Session Termination” and 3.13.9 “Network Session Termination”.
They seem similar, but 3.13.9 controls the risk using crunchy network and firewall settings while 3.1.11 controls the risk using server-side methods to log off or disable accounts.
In this video, Jil Wright, Certified CMMC Assessor extraordinaire, and Amira Armond, Certified CMMC Assessor and Kieri Solution’s Quality Manager, explain the difference!
Did someone tell you that you have to disconnect all your VPNs every 24 hours in order to be compliant with CMMC? Terrible! Sure, it is one way to be compliant, but there are better ways to do this!
Spread the word, the confusion about these two requirements needs to be fixed.
Amira Armond is the founder and Quality Manager for Kieri Solutions, an Authorized C3PAO. Jil Wright is a Certified CMMC Assessor and instructor with Wrightbrained Security. Kieri Solutions provides CMMC preparation and assessments for CMMC and 800-171 compliance.
The wait is finally over! Listen to our industry experts review the CMMC Proposed Rule, what it means for you and what changes or surprises are in store. Our team here at Kieri, under the guidance of Amira Armond, spent the Holiday sifting through the rule to give you a detailed synopsis of what we think you need to know. This release will have such meaningful impact on the DIB that we are not going to wait until the new year to discuss it. Tune in and our assessment team will give you their thoughts and observations so you can better understand and plan for how CMMC will effect you.
Kieri Solutions offers a licensable set of 800-171, DFARS 252.204-7012, and CMMC compliance templates called the Kieri Compliance Documentation (KCD). This is a holistic and user-friendly cybersecurity program which is designed for small and medium networks (less than 1000 users).
Check our main KCD page for FAQ, business justifications, customer testimonials, price, and more!
The below video has a demo of the real KCD documents so you can see exactly how the program works. It is also good standalone training for what a nice System Security Plan, record keeping, and policies look like.
I am hearing that Microsoft Defender ate everyone’s Outlook shortcut this morning if they had enhanced security enabled (Attack Surface Reduction rules in Microsoft 365 / Intune).
To quickly resolve, re-create the shortcut from the original Outlook.exe file
To do this:
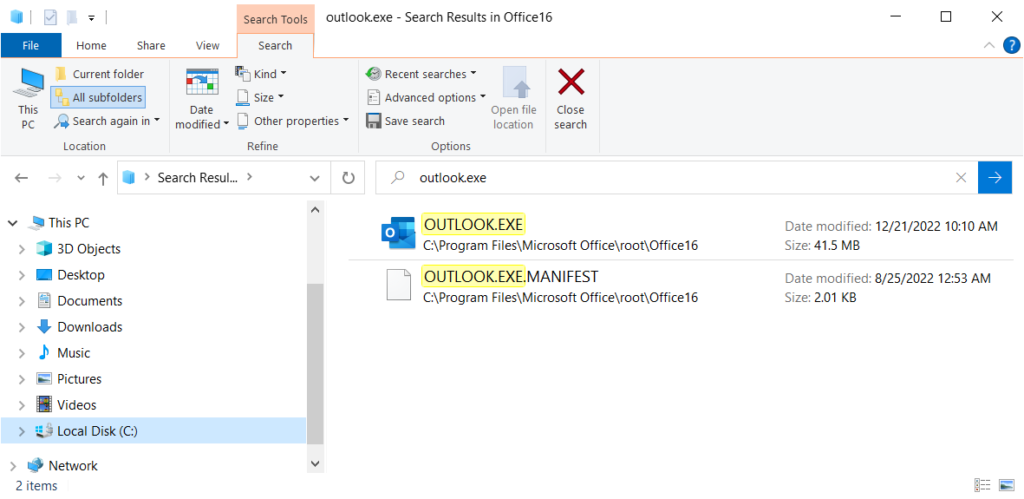
1. Open Windows Explorer
2. In the search bar, search for “Outlook.exe”
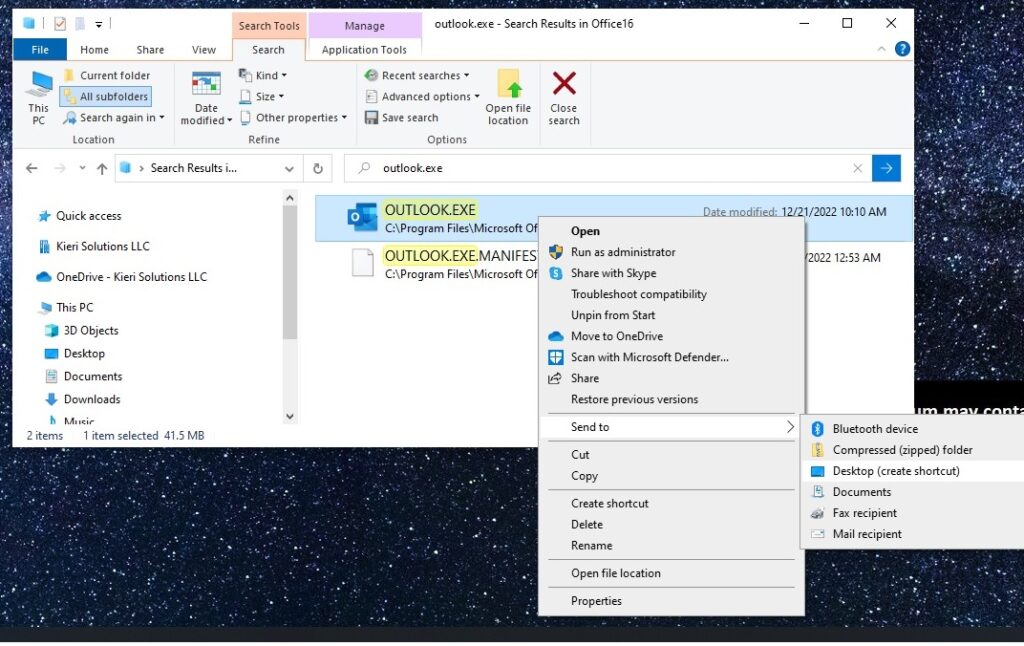
3. Right-click OUTLOOK.EXE and “Send to” >> “Desktop (create shortcut)”
Now you should be able to open Outlook using the file on your desktop.
4. You can right-click the file on your desktop and “Pin to Taskbar” or “Pin to Start” to make it more convenient.
Please limit yourself to 1-2 people per organization. The meeting can only handle 300 participants. If you can’t get in, check the Stakeholder Forum meeting channels for secondary streams. This is a LIVE event only.
Kieri Solutions LLC has included the NIST SP 800-171 DoD Assessment methodology in our compliance programs since the DCMA started publishing it in early 2020.
The just-published DFARS Interim Rule requires self-assessments to be submitted to the DoD as a pre-requisite for contract award.
For full details and links to sources, please see this article on CMMCaudit.org, written by Amira Armond (President of Kieri Solutions):
As a DoD contractor, you need to take action immediately in order to continue winning contracts
Note: All of these actions should be performed by a senior-level cybersecurity expert, either on-staff or consultant.
Have a System Security Plan which describes your environment and addresses all 110 requirements in the NIST SP 800-171. This plan is normally 100+ pages for a business with >50 employees.
Have a Plan of Action & Milestones which describes a full plan to achieve 100% compliance with NIST SP 800-171 and DFARS 252.204-7012
Perform a self-assessment using the NIST SP 800-171 DoD Assessment Methodology
Submit these documents and your self-assessment score to the DoD prior to your next contact award. (Ideally a few weeks ahead, so they can process it)
Kieri Solutions program for NIST SP 800-171 and DFARS 252.204-7012
Our cybersecurity compliance program is designed to help organizations become DFARS 252.204-7012 / NIST SP 800-171 compliant.
Our first priority is DFARS 252.204-7012 and NIST SP 800-171 self-assessment
Our overall program is designed to get you CMMC compliant
These two sets of compliance regulations are complimentary, with a straightforward progression from one to the next.
Kieri Solution’s standard compliance program includes these major deliverables:
Perform gap analysis and create an action plan to get your organization started on implementation projects as soon as possible.
Write the System Security Plan and Plan of Action & Milestones
Conduct a DoD self-assessment and help you report it to the DoD
Train and guide your IT leadership (CISO, CIO, Compliance Officer) to represent your company during an audit, and to support internal processes demonstrating cybersecurity maturity.
Provide customized policies, procedures, and user agreements which address all CMMC Level 2 “Advanced” and NIST SP 800-171 requirements
NIST SP 800-171 compliance is complex
Many companies don’t have the cybersecurity expertise in-house to fully understand what is required by NIST SP 800-171.
They don’t have a real system security plan, or the person assigned to create it only addressed a small portion of the in-scope environment.
Submitting a false claim is punishable
The Federal Justice Department describes penalties of “double the government’s damages” for false claims. The DoD has repeatedly said that falsely attesting to DFARS 252.204-7012 compliance is punishable under the false claims act.
Next steps: Schedule a free 30 minute consultation
Our president, Amira Armond, is making herself available for 30 minute consultations with DoD contractors that are concerned about cybersecurity compliance.
Symptom: You start seeing the alarm “vSphere Health detected new issues in your environment” and it won’t go away.
I wrote about this alarm with one cause: Memory Exhaustion with a Tiny deployment in my other blog. If you navigate to your vCenter appliance website (https://vcenter.company.com:5480) and see memory warnings, check the fix in that blog first.
Symptom: You recently upgraded to vCenter or vSphere ESXi 6.7 U2 (Update 2, April 2019, May 2019)
Symptom: Warning in event logs “Alarm ‘vSphere Health detected new issues in your environment’ on Datacenters changed from Green to Yellow”
Symptom: Warning in event logs: “event.vsphere.online.health.alarm.event.fullFormat (vsphere.online.health.alarm.event)
Symptom: You don’t see anything to explain the issue in the logs. Looks like a false positive?
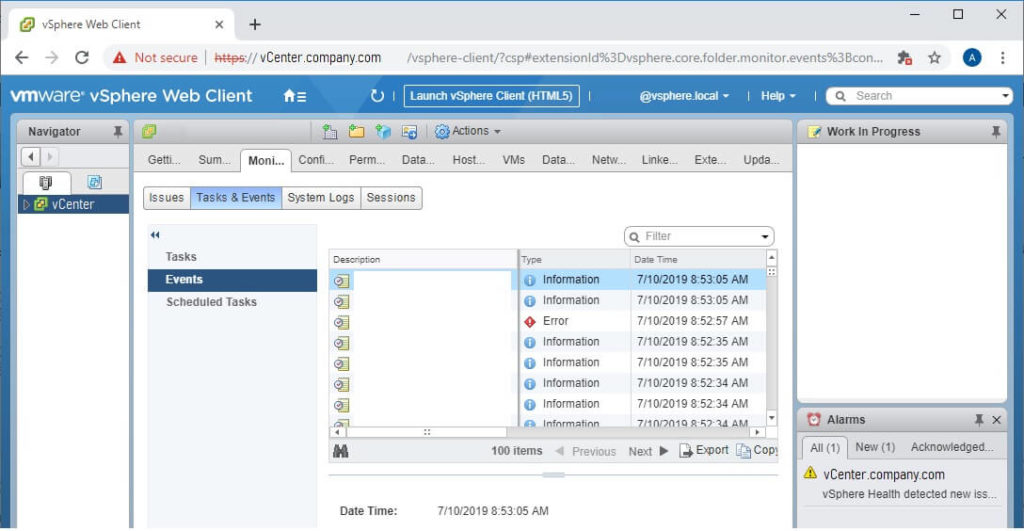
Symptom: When you navigate to vCenter > Monitor > Health, there is no health tab.
This is the main symptom for this particular issue. Read on!
Root Cause #1: You are still using the Flash vSphere client from version 6.0 and 6.5.
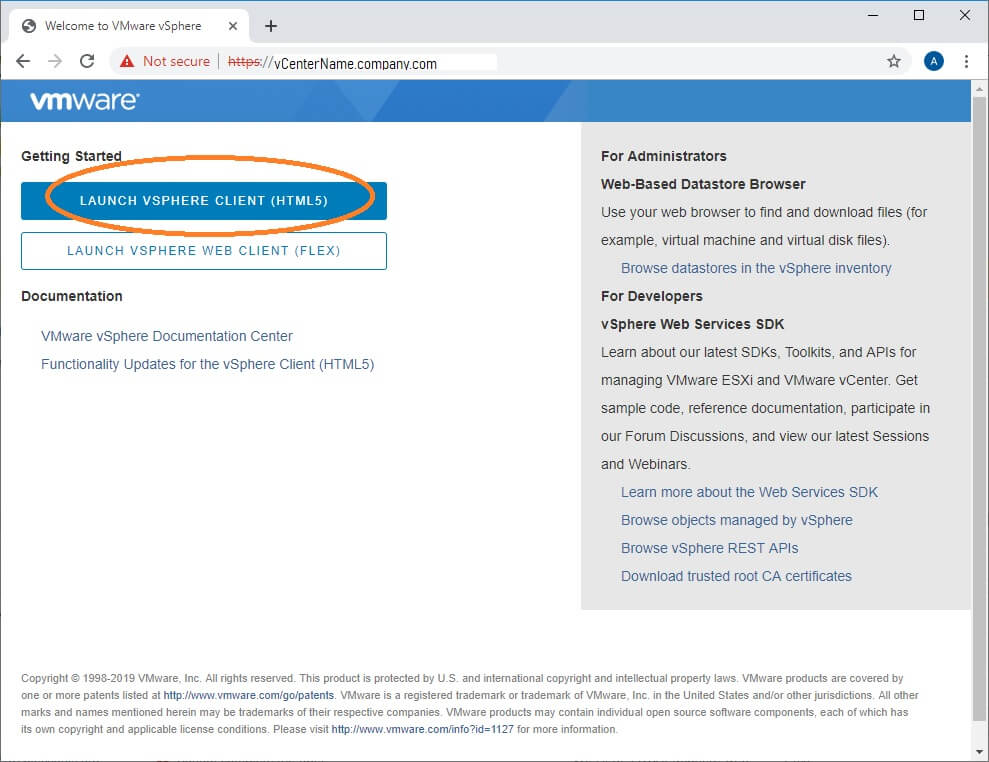
You need to change the URL you are using for vSphere and vCenter: https://vCenter.company.com/ui
You can find this URL from scratch by navigating directly to your vCenter: https://vCenter.company.com and clicking the HTML5 button
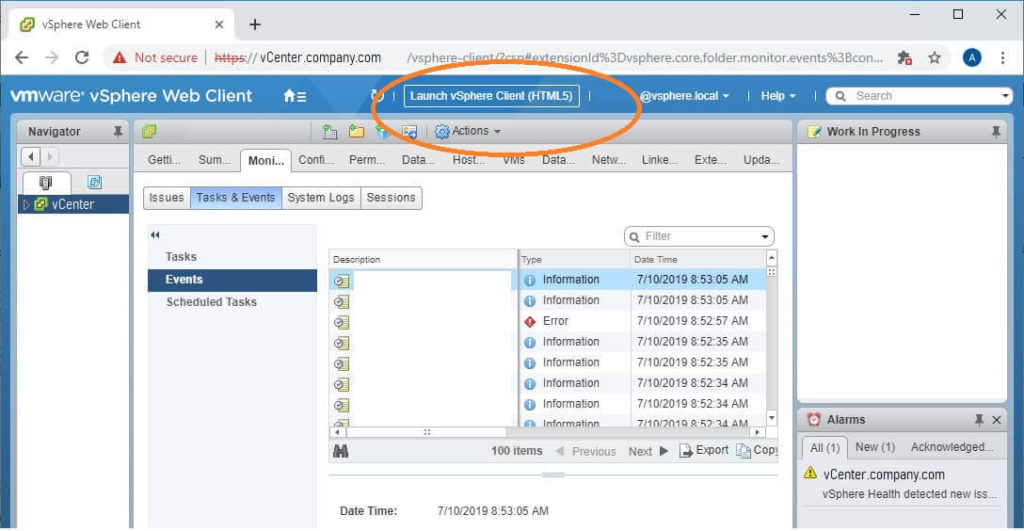
You can also find it right at the top of your vSphere website – Look for a button that says “Launch vSphere Client (HTML5)”
Now that you’ve launched the HTML5 site, you will notice that it looks way different!
Root Cause #2: The latest updates for vCenter and vSphere include new checks for common issues.
The April 2019 and May 2019 release of 6.7 Update 2 include new health checks. Your vCenter will now warn you about things like problematic drivers and known memory leaks.
These checks are only visible in the HTML5 client. This is why you couldn’t find the cause of the alert before. Read on for how to find them.
These checks are also handled by the Customer Experience Improvement Program (VMware CEIP). If you are a typical business (not at high risk from cyber-attack), the CEIP program is highly recommended. If you are at risk from cyber-attack, there are ways to secure the CEIP connection so you can still use it.
How to troubleshoot the cause of vSphere Health detected new issue in VMware 6.7
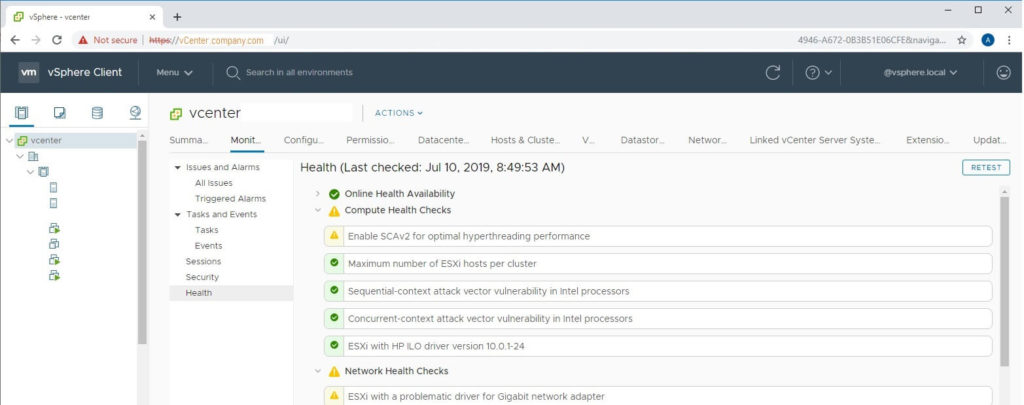
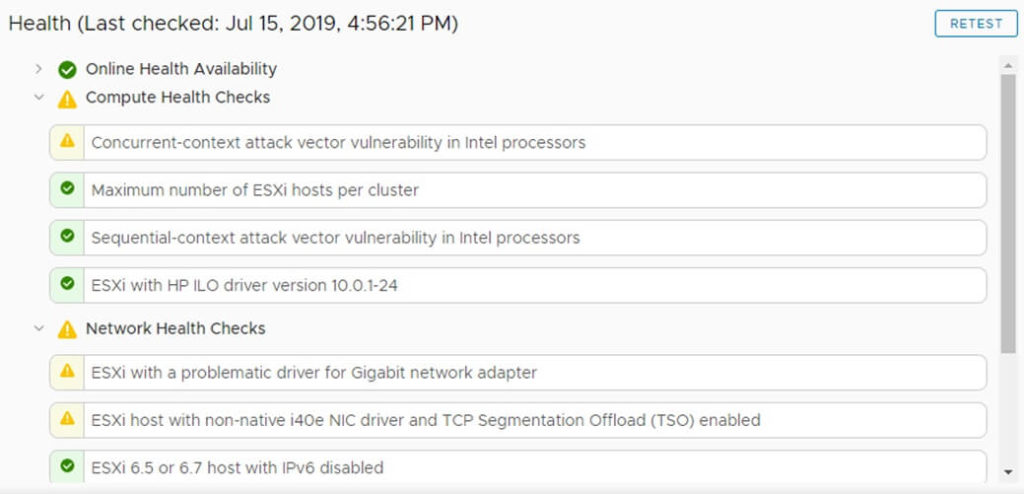
When you open the HTML5 vSphere Client, you will now be able to navigate to Monitor > Health and see what is causing your health alarm.
Using the instructions above, open your HTML5 vSphere client by navigating to https://vcenter.company.com/ui
Select your vCenter object in Hosts & Clusters view. (This is the top level object in your tree)
Click the Monitor button from the middle menu.
Click the Health button from the middle-middle menu.
Identify warnings that have yellow exclamation marks next to them. These are causing your health alarm.
You can click each item to view information about them. If you select the Info tab for that problem, you will see a button for “Ask VMware” which gives additional help.
Click the RETEST button on the top-right of the window to see if the issue still exists.
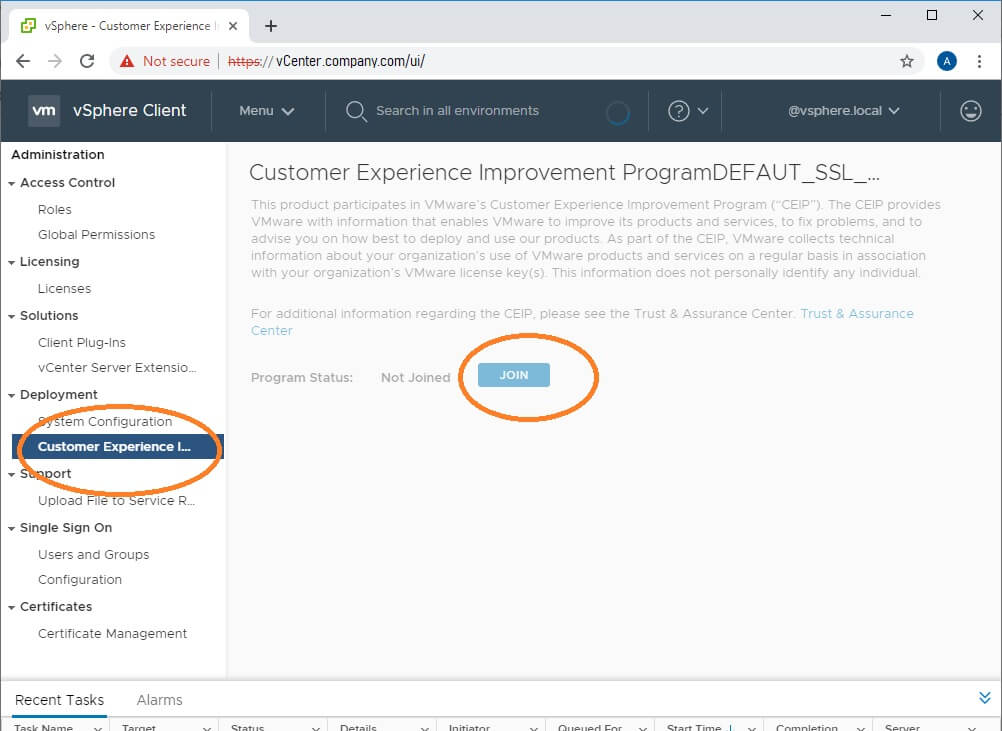
How do I enable CEIP for VMware?
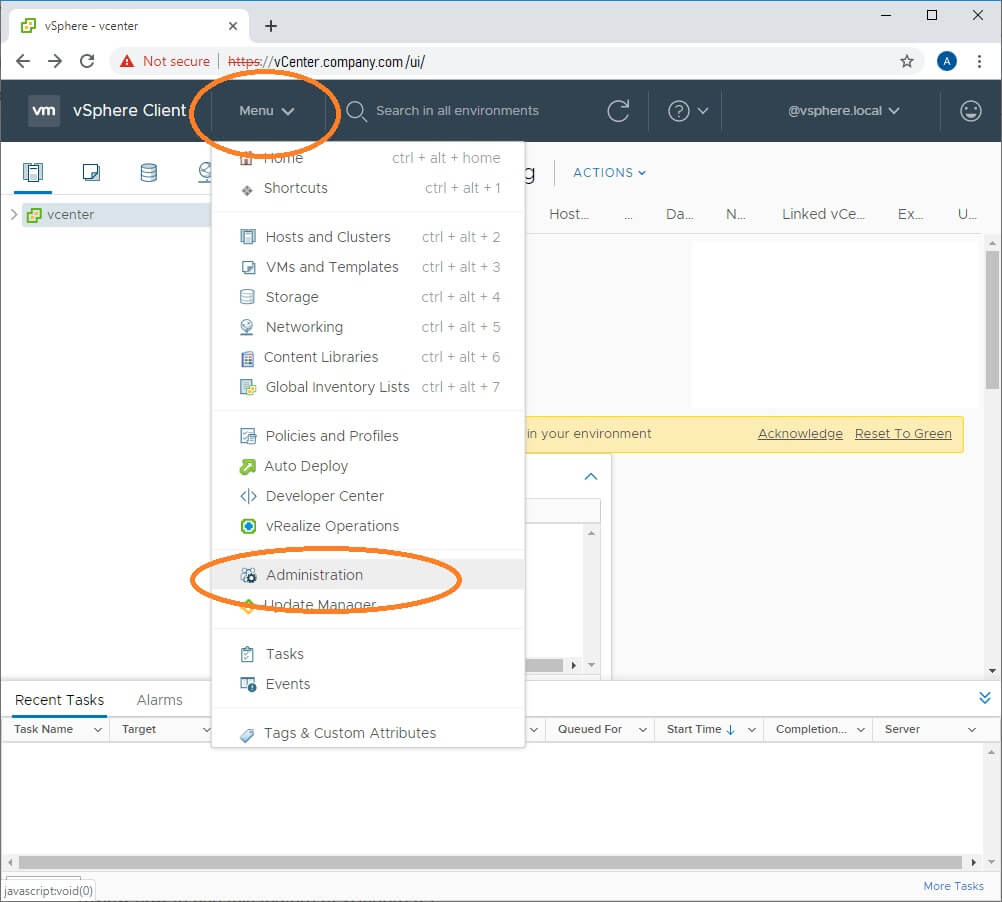
From the vSphere HTML5 Client, click the Menu drop-down button
Navigate to Deployment > Customer Experience Improvement Program
Click Join…
This VMware blog has a nice video of how to click through and enable CEIP if you are having trouble.
How do I fix “Enable SCAv2 for optimal hyperthreading performance”?
This is a continuation of the SPECTRE/MELTDOWN or “L1 Terminal Fault” issue that you’ve heard about.
WARNING: VMware default settings are for highest performance. If you make changes to increase security against SPECTRE / MELTDOWN, your performance may be impacted significantly! In other words, if your virtual environment is using more than 20% CPU at any given time, you should probably NOT enable these changes without a lot of research.
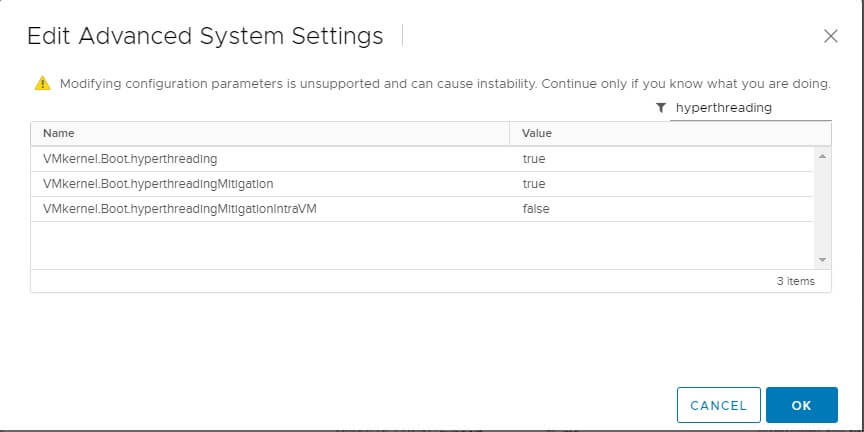
You probably have already applied the fix for previous versions of vSphere. The fix was to edit Advanced System Settings for each host and change the value of VMkernel.Boot.hyperthreadingMitigation = true
In 6.7 Update 2 and later, VMware added VMkernel.Boot.hyperthreadingMitigationIntraVM which defaults to true.
To enable SCAv2, you would verify that VMkernel.Boot.hyperthreadingMitigation = true and change the VMkernel.Boot.hyperthreadingMitigationIntraVM = false and reboot each host.
This setting can be reached by opening vSphere Client website (https://vcenter.company.com/ui) then select Hosts & Clusters view, then select a host. Click the Configure tab and select Advanced System Settings from the middle menu. Repeat for each host.
How do I fix “ESXi with a problematic driver for Gigabit network adapter”?
Follow the Ask VMware link on the alert to find specific information about your problematic network card.
It will open a VMware KB article and probably recommend installing an updated driver.
To update to a new driver, here are the basic steps… please use caution and common sense!
Download the VIB file from VMware
While you are at it, download the README and review it. If it has instructions, follow those.
If it is in a .zip format, unzip it and find the .vib file
Move your VMs to a different host if possible.
Put your ESXi host into maintenance mode (this procedure could cause impact to any running VMs)
Back up your ESXi host configuration if you still have any VMs on it (in other words, you can’t afford to rebuild it if something goes wrong).
Start SSH service in your host > Configuration > Security Profile menu.
Using WinSCP or another reliable SCP client, connect to your host using IP and root / (root password)
Navigate to the /tmp/ directory and upload the VIB file to that directory.
Using Putty or another reliable SSH / console client, connect to your host using IP and root / (root password)
If your VIB doesn’t say “offline bundle”, type esxcli software vib update -v \tmp\NameOfVIBFile.vib
If your VIB says “offline bundle”, type esxcli software vib update -d \tmp\NameOfVIBFile-offline_bundle.vib
Read the results.
If the the result says “Reboot required: true” , then type reboot (this will reboot your host)
Make sure to test your host with a non-critical VM before moving important VMs to it.
How do I fix “Concurrent-context attack vector vulnerability in Intel processors”?
This error is referring to the “L1 Terminal Fault” which is widely known as SPECTRE / MELTDOWN.
Basically, there is a flaw in all Intel Processors (at least as of late 2018) which allows processes running in the operating system to observe what the CPU is doing with other processes. This is a critical vulnerability for cloud hosts or any servers that allow untrusted users to access them.
L1 Terminal Fault a major concern for cloud hosting companies, not on-premises companies
For example, if you have an account on AWS, your virtual servers are running on the same physical hardware as other people’s virtual servers. If this vulnerability isn’t mitigated, then you could potentially write code to steal data from the other customers, or vice-versa.
To my knowledge, the vulnerability cannot be exploited without running a process on the system, and most of the people who run processes on servers have no need to snoop on the CPU. In other words, if all the other admins on your server work at your company, you should be fine.
What is the fix?
For now, while the physical processors have this flaw, the fix is to logically reduce the hyper-threading capability of Intel CPUs so they can’t be snooped on. This removes 5-20% of the performance capacity of the CPU.
If your VMware environment isn’t really using the CPU (peak CPU on your hosts is less than 30%), go ahead and implement the fix!
If your servers ARE using the CPU intensively (peak CPU is greater than 30%), then think hard before making a change.
To implement this fix, edit Advanced System Settings for each host and change the value of VMkernel.Boot.hyperthreadingMitigation = true , then reboot the host. Since you are already at 6.7 Update 2, your health alarm will probably change to “Enable SCAv2 for optimal hyperthreading performance” which is addressed a few sections above this one.
What if I don’t want to fix concurrent context?
Some environments cannot afford to lose the CPU performance. For example, I have a client that runs a lab environment with extremely high processing requirements. The hosts are running 70%+ CPU constantly.
So how can you remove the vSphere health warning about concurrent-context attack vector?
Event: “Alarm ‘vSphere Health detected new issues in your environment’ on Datacenters changed from Green to Yellow
Even on healthy vCenters, you will see this event appear about once a week. In my environments it lasts for about one hour (green to yellow, then yellow to green). It doesn’t appear to be an actual issue.
Selfish plug time – Need help?
I am a consultant in the Maryland/DC area in the USA. My specialties are Windows migrations (to 2016 and to Office 365 / Azure), VMware migrations, Netapp and SAN, and high availability / disaster recovery planning. If you would like help with your complex project, training, or would like a architectural review to improve your availability, please reach out! More information and contact can be found on the About page. – Amira Armond
I’m starting to see vSphere health warnings complaining about the “Depreciation of the external Platform Services Controller deployment model”
This is very confusing because my vCenter servers were built using the Embedded Platform Services Controller option. Yet vSphere health is saying that there is a problem?
Symptoms:
vSphere health warning for external platform services controller
The Skyline Health description text reads:
“Starting with vSphere 6.7, VMware announced a simplified vCenter Single Sign-On domain architecture by enabling vCenter Enhanced Linked Mode support for vCenter Server Appliance installations with an embedded Platform Services Controller. You can use the vCenter Server converge utility to change the deployment topology from an external Platform Services Controller to an embedded Platform Services Controller with support for vCenter Enhanced Linked Mode. As of this release, the external Platform Services Controller architecture is deprecated and will not be available in future releases. Click the Ask VMware link above for more details and a resolution.”
vSphere health alert for Upgrading Load Balanced PSCs
The Skyline Health description text reads:
“Special steps need to be taken when upgrading a vSphere 6.7 environment that has external, load-balanced Platform Services Controllers to vCenter Server 7.0. Click the Ask VMware link above for more details and a resolution.”
How do I tell if my vCenter uses an external or internal PSC?
Navigate to your vCenter appliance management website:
https://vCenteraddress:5480
You should be able to log on with your normal vSphere credentials (typically username@vsphere.local)
Navigate to the Summary page. In the top middle area, you will see “Type: vCenter Server with an embedded Platform Services Controller”
If your server uses an external PSC, it will say that here as well.
Synology SA3400 SAN connected to VMware vSphere ESXi 6.7 using iSCSI
This is a new install. The issues have been occurring since you started using the Synology for VMware datastores
Event: Device or filesystem with identifier x has entered the All Paths Down state. Warning
Event: Lost connectivity to storage device . Path vmhba64:C0:T1:L1 is down. Affected datastores: Synology_Datastore1. Error
Event: Lost access to volume due to connectivity issues. Recovery attempt is in progress and outcome will be reported shortly. Information
Event: Alarm ‘Cannot connect to storage’ on 10.41.89.34 triggered an action Information
Event: Alarm ‘Cannot connect to storage’ on 10.41.89.34 triggered by event 615108 ‘Lost connectivity to storage device naa.6001405de561547da144d4199dac86d6. Path vmhba64:C0:T1:L1 is down. Affected datastores: Synology_Datastore1.’ Error
VMware performance monitor shows regular extreme disk latency spikes (500ms, 20,000ms) every few minutes.
Occasional vCenter alarms will display showing that a host has lost connectivity to storage. Normally only one host and one iSCSI datastore LUN at a time.
On the Synology side, the Resource view shows no latency spikes.
Root cause
In my experience, this is caused by VMware attempting to perform ATS Heartbeat checking against the Synology (which does not support it).
This issue may also affect EMC and IBM storage providers.
After ESXi 5.5, the VMware VMFS version updated from 3 to 5. One major difference between them is that VMFS5 has the “ATS heartbeat” setting default to on, which offloads the datastore heartbeat feature to the storage provider. According to this VMWARE KB link below,
“This optimization results in a significant increase in the volume of ATS commands the ESXi kernel issues to the storage system and resulting increased load on the storage system. Under certain circumstances, VMFS heartbeat using ATS may fail with false ATS miscompare which causes the ESXi kernel to again verify its access to VMFS datastores. This leads to the Lost access to datastore messages.”
Storage provides like EMC, and IBM are already asking their users to disable this feature on VMFS5 datastores due to the problems encountered:
Refer to the instructions in the VMware Knowledge Base in the following link to disable the ATS Heartbeat:
When I performed this change, it took about 5 minutes, did not need a host reboot, did not cause any impact. The latency spikes and storage disconnects stopped immediately.
This is a solution by Greg Baharoff, the owner of MTBW Services Inc. in Mount Airy, Maryland.
Symptom: During maintenance, the Windows Server became stuck in recovery mode.
Symptom: The following “regular” solutions did not work, such as bootrec /rebuildBCD , sfc /scannow , and dism.exe /cleanup-image.
Symptom: Datto driver / agent was installed on the server before it went into recovery mode.
Root cause for Windows Recovery Mode after Datto install:
It looks like the Datto agent installed on the server was unsigned, or had an invalid signing certificate, which made Windows crash into recovery mode.
Here are the regular solutions for this problem, that normally work. At the bottom of this article are the steps to fix the Datto agent issue.
bootrec /rebuildBCD
Booting with a Windows 2008 R2 recovery DVD, the following steps allow the machine to boot normally.
Put the Windows Server 2008 R2 installation disc in the disc drive, and then start the computer.
Press any key when the message indicating “Press any key to boot from CD or DVD …”. appears.
Select a language, time, currency, and a keyboard or another input method. Then click Next.
Click Repair your computer.
Click the operating system that you want to repair, and then click Next.
In the System Recovery Options dialog box, click Command Prompt.
How to fix the driver signing issue causing Windows recovery mode, related to Datto Agent
It has to do with driver signing.In my case I had installed a new driver – Datto Agent. I restarted and BOOM! Recovery, recovery, recovery, recovery…
Fix: Boot up the server, hit the F8 key a few times to get the Windows boot options. Then choose “Disable Driver Signature Enforcement”.
That got me into Windows….
The Datto Agent started and is working at this point. I didn’t do anything to “fix” the system after I was finally able to login after Disable Driver Signature Enforcement.
The long term solution is to make sure the system certificates trust your Datto agent software then re-enable driver signature enforcement. Installing a different version may be necessary.