Symptom: You are using ONTAP 9x (your Netapp is fairly new, within the last 4-5 years. These instructions probably don’t apply to old Netapp devices)
Symptom: When you look at the diagnostic logs on your Netapp, you get a warning that the certificates are expiring or expired:
Event: mgmtgwd.certificate.expiring: A digital certificate with Fully Qualified Domain Name (FQDN) ExampleNetappServer1, Serial Number 569848B0A5092, Certificate Authority ‘ExampleNetappServer1’ and type server for Vserver ExampleNetappServer1 will expire in the next 29 day(s).
Message Name: mgmtgwd.certificate.expiring
Description: This message occurs when a digital certificate for a Vserver is about to expire. Client-server communication will not be secure if the certificate expires.
Action: Install a new digital certificate on the system using the ‘security certificate create’ or ‘security certificate install’ command.
Symptom: When you try to reach the website for your Netapp OnTAP, it won’t connect at all.
See the image above for what this looks like.
Symptom: You tried to create new certificates using security certificate create and now the website is broken.
Whoops. Never fear, keep reading, this article will help you.
DIFFERENT ISSUE — Third Party CAs are expiring
Just recently (June-July 2019), ONTAP users are getting errors that several certificates of type “server-ca” are expiring. These are NOT the certificates you use for your Netapp website and the fix steps in this article do not apply to them.
When prompted, type your administrator username and password. admin is the default username and netapp!123 is the default password.
Disclaimer: I’m just someone who admins Netapp SAN for my job. You should review the official Netapp articles on this topic and use common sense before making changes. If you aren’t sure about anything, put in a case with Netapp to get help.
Here are the commands you will run to see the current status of your certificates:
security certificate show
ssl show
Feel free to run these whenever needed, to see your status.
Run both commands now and screenshot or copy the results so you can reference them later.
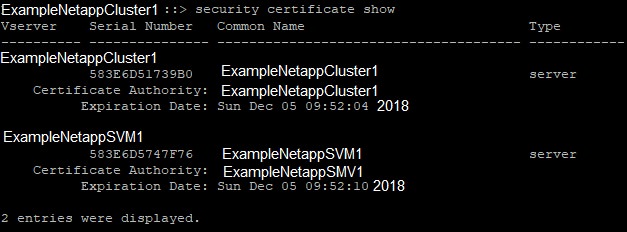
Here is an example of a Netapp that has expired certificates for the cluster and the SVM:
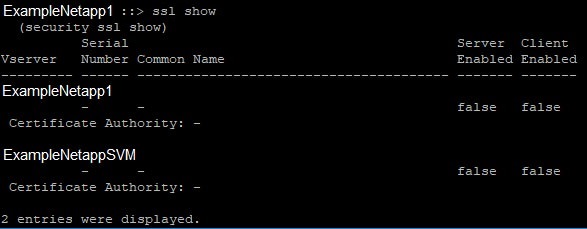
Here is an example of a Netapp that has broken website ssl certificate:
.
Did you already delete your certificates and don’t know the names of your cluster and SVM?
Assuming you are connecting to your cluster, you should see the cluster name at the beginning of your command prompt.
If you press TAB while writing a command, Netapp will provide you possible answers. This can help you retrieve your Vserver list.
Type security certificate show -vserver [TAB]
Your command prompt will show you the possible answers. One should be your cluster, one should be your SVM(s).
Perform these steps to get rid of expired certificates, install new, and enable.
1. Delete old certificates:
Identify your variables:
-vserver = vserver name from the “security certificate show” command, such as ExampleNetappCluster1
-common-name = common name from the “security certificate show” command, such as ExampleNetappCluster1
-serial = serial number from the “security certificate show” command, such as 448293BA028
-type = type from the “security certificate show” command. Self-generated certificates are type server.
Run command for your cluster certificate: security certificate delete -vserver ExampleNetappCluster1 -serial ########## -type server -common-name ExampleNetappCluster1
When prompted, type Y to delete.
Run the command again for each SVM certificate: security certificate delete -vserver ExampleNetappSVM1 -serial ########## -type server -common-name ExampleNetappSVM1
When prompted, type Y to delete.
2. Create new self-signed certificates:
Run command for your new cluster certificate: security certificate create -vserver ExampleNetappCluster1 -common-name ExampleNetappCluster1 -type server -expire-days 999
You can change the expire-days per your security policy. The default is 365.
Run command for each new SVM certificate: security certificate create -vserver ExampleNetappSVM1 -common-name ExampleNetappSVM1 -type server -expire-days 999
3. Enable SSL with the new certificates:
Run command for your new cluster certificate: ssl modify -vserver ExampleNetappCluster1 -server-enabled true
Run command for each new SVM certificate: ssl modify -vserver ExampleNetappSVM1 -server-enabled true
4. At this point, your website should be back up!
Please leave comments if this worked for you, or tips if it didn’t.
If you need further reference, I found these Netapp articles helpful.
Thanks for reading this article! I hope it helps you! If you have tips or feedback, please comment or send me an email so that others can benefit.
I am a consultant in the Maryland/DC area in the USA. My specialties are Windows migrations (to 2016 and to Office 365 / Azure), VMware migrations, Netapp and SAN, and high availability / disaster recovery planning. If you would like help with your complex project, or would like a architectural review to improve your availability, please reach out! More information and contact can be found on the About page. – Amira Armond
Many websites will say that vCenter 6x requires DNS lookup, but these steps and screenshots prove that you can install a new vCenter 6.7 with only an IP address and no DNS.
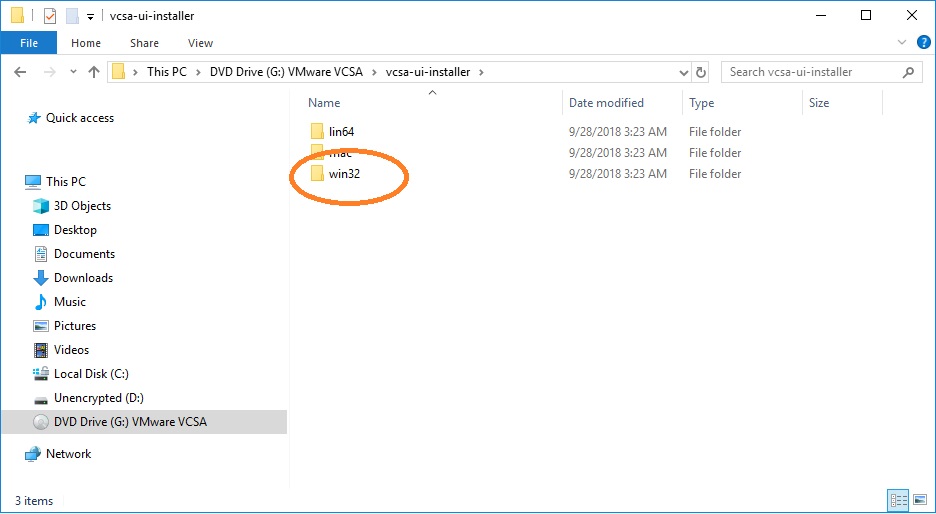
Start vCenter install from .iso file using Windows 10
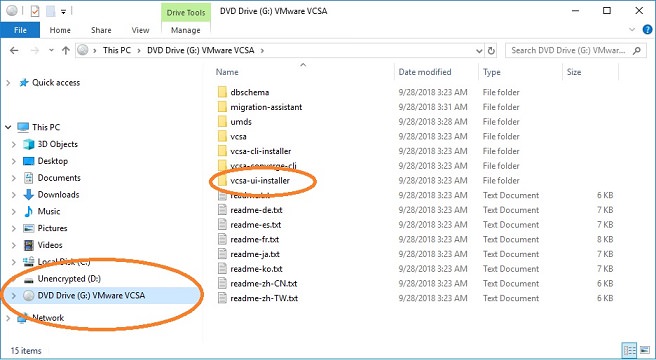
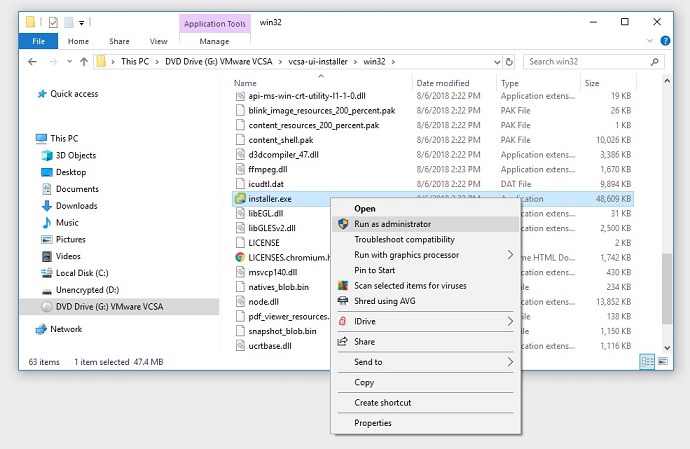
1. Download the install .iso file for your vCenter (available from the downloads area of vmware.com. On a Windows PC (I am using Windows 10), double-click the .iso file to mount it. It will show up in a virtual DVD drive.2. Open your virtual DVD drive and expand the vcsa-ui-installer folder.3. Expand the win32 folder (for a Windows PC). If you are using Linux or Mac as your desktop, select the appropriate folder.4. Run the installer.exe file as administrator (on Windows). This will start the program that allows you to deploy, upgrade, or migrate vCenters.
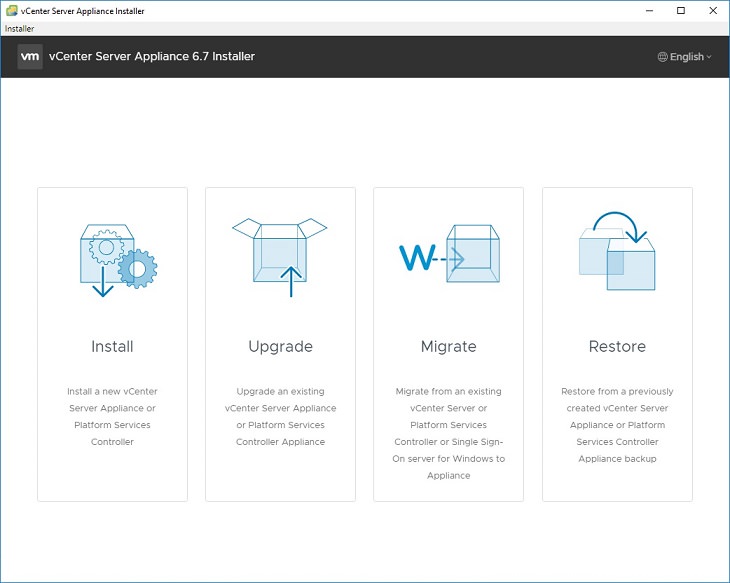
vCenter install stage 1
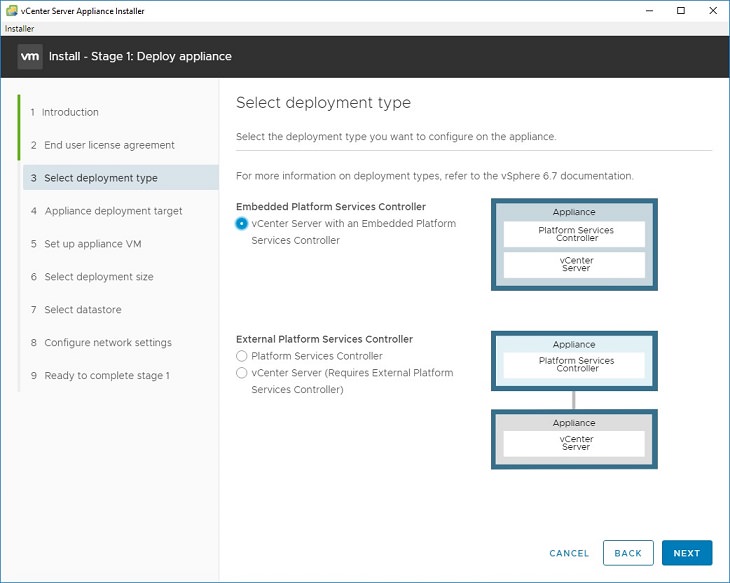
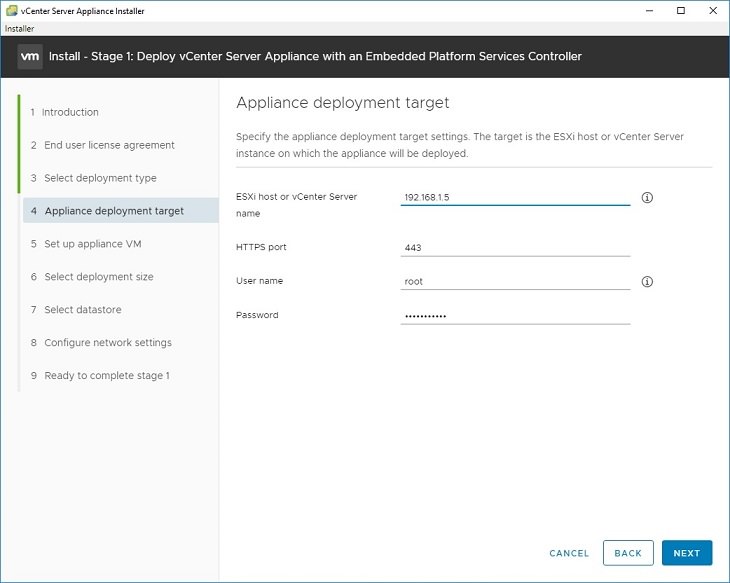
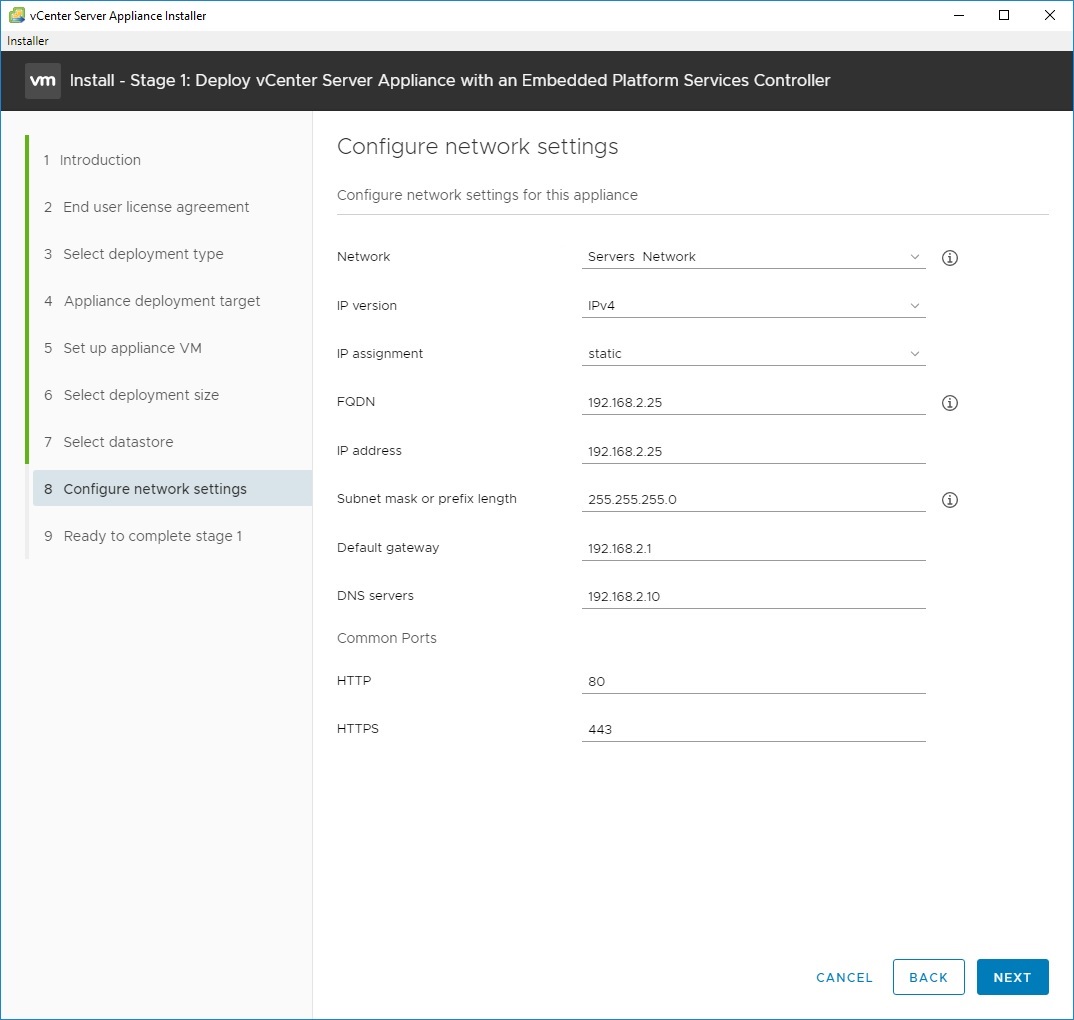
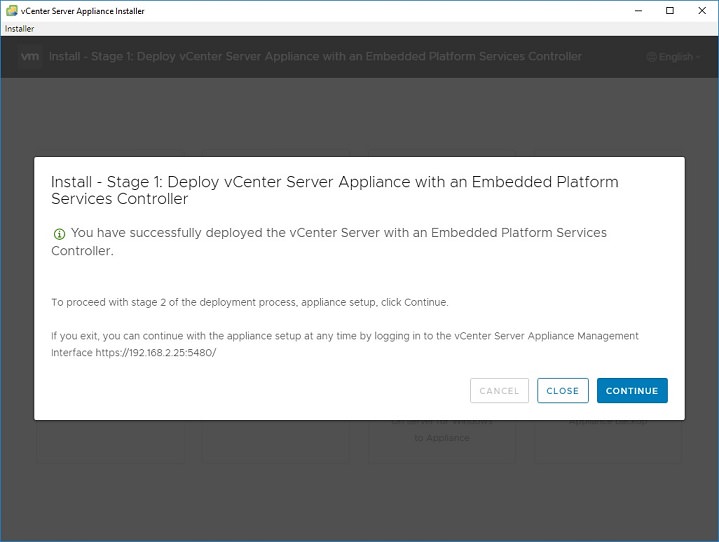
5. Initial options display. In our case, we are installing a brand new vCenter with no DNS, only IP address. So pick Install.6. Go through the introduction and end use license agreement. For the deployment type, select Embedded Platform Services Controller (this is normally the correct choice unless you have a very large, complex environment)7. Normally you will be installing a new vCenter directly onto an ESXi host. Put the IP address of your ESXi host into the “ESXi host or vCenter Server name”. Leave the port 443, enter the correct root account and password for that ESXi host. 8. Configure options for “set up appliance VM” — this gives the name for the VM on your host (and will affect naming of the datastore folders). Set the root password for the vCenter appliance here. Select deployment size – for most situations, the default of Tiny is fine unless you have more than 10 hosts. Select datastore – pick the datastore to create the VM into.9. Configure network settings: Here is the important part. Network should be a virtual port group (switch) that your desktop can communicate with. IP assignment should be static. In the FQDN field, enter the IP address of your vCenter server. In the IP address field, enter the IP address of your vCenter server. Enter the rest of the fields as appropriate for your environment. If you don’t have a DNS server at all, use your gateway or another bogus IP.10. Confirm your settings and start deployment. For me, I was able to complete Stage 1 in about 15 minutes, despite using a slow (100mbps) network.
vCenter installation stage 2
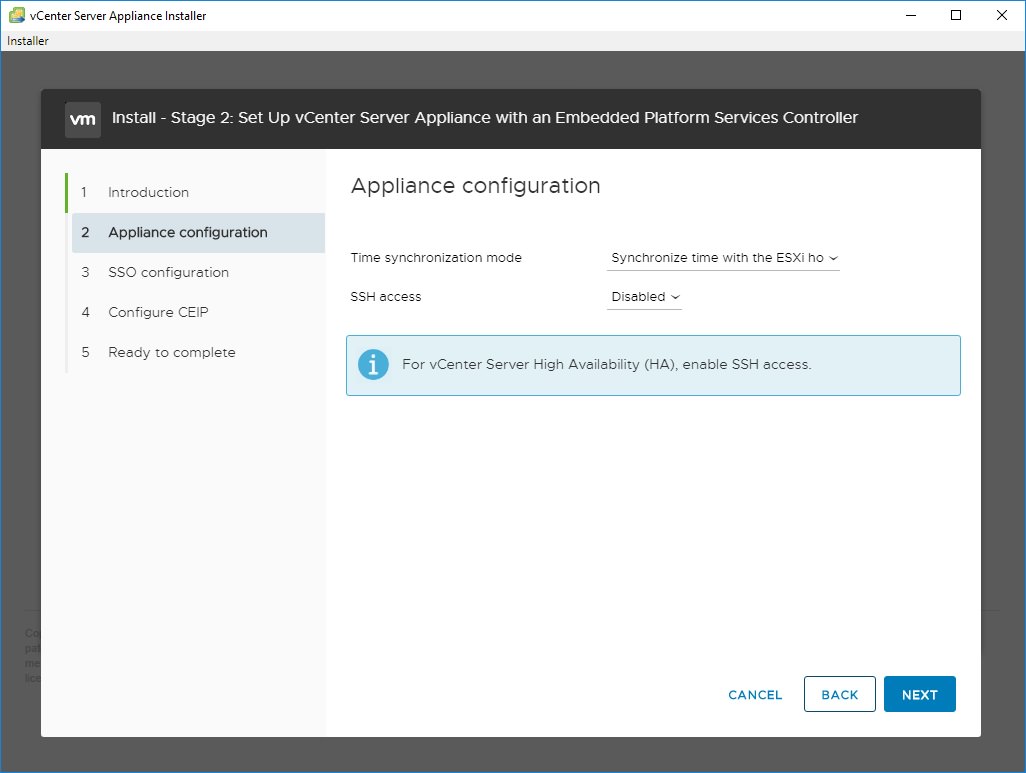
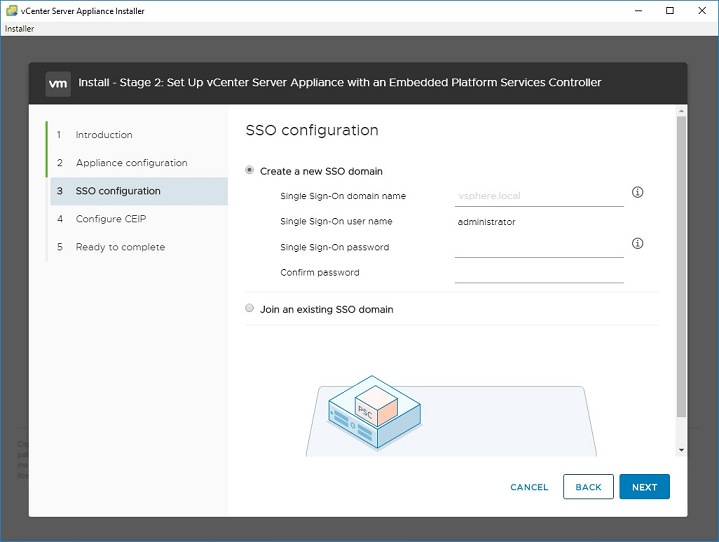
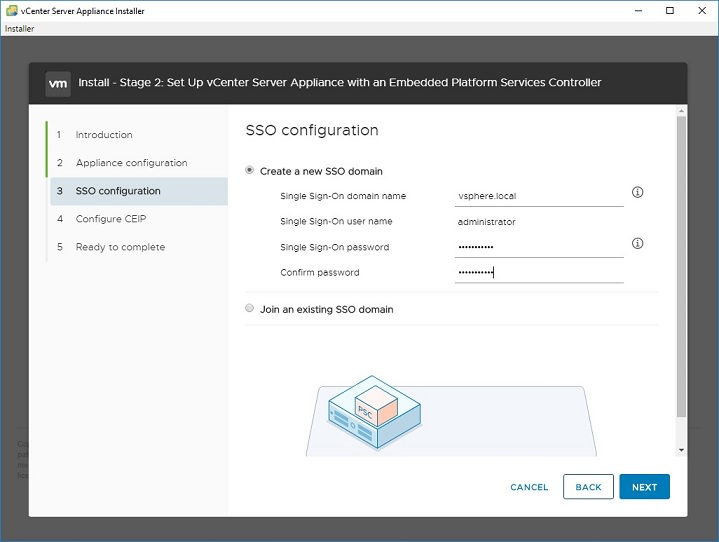
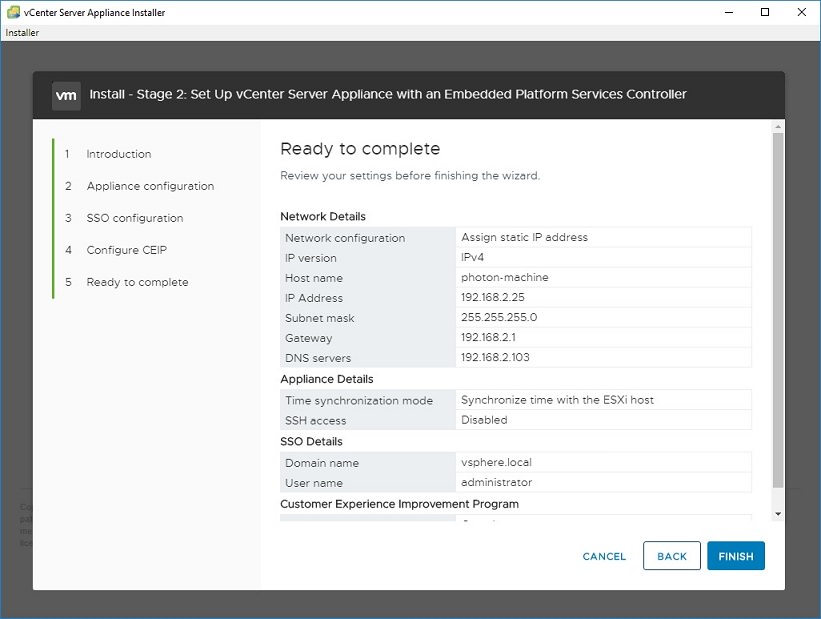
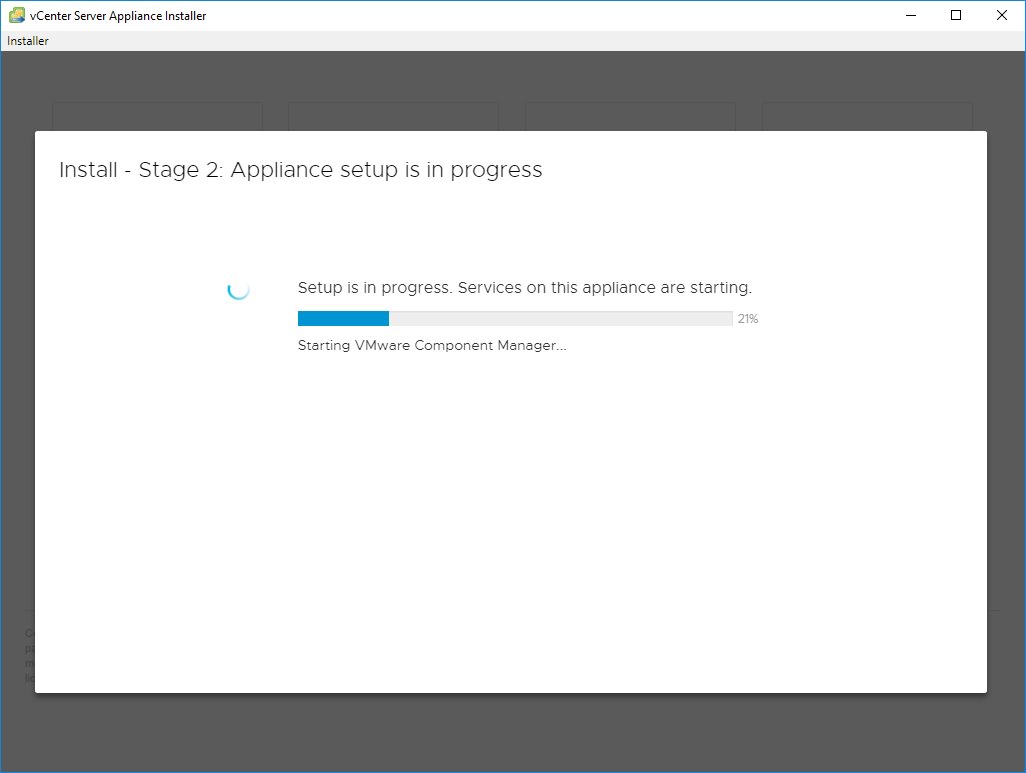
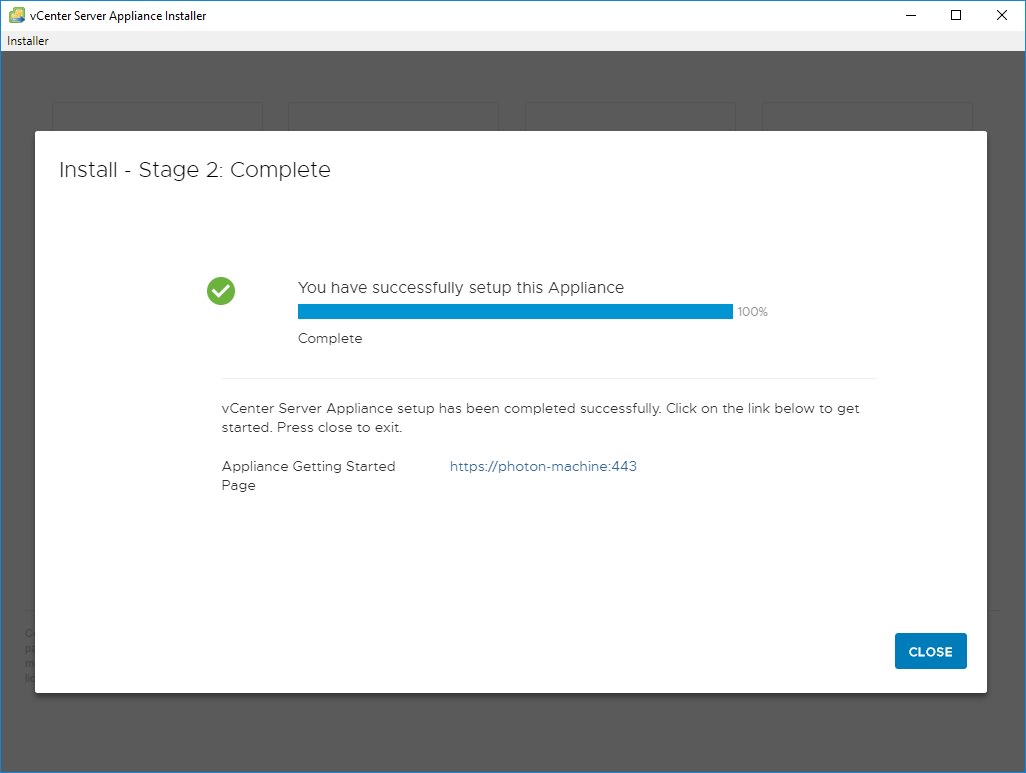
11. Stage 2 starts. If you have an NTP server, set it here, otherwise make sure your ESXi host has correct time and use it.12. Most deployments create a new SSO domain.13. Enter “vsphere.local” into SSO domain name, enter a password for administrator. Your logon username will be administrator@vsphere.local with the password you set.14. Select whether you want to participate in the Customer Experience Improvement Program (secure facilities say no). Then review your settings and Finish to start configuration.15. How long does it take to complete Stage 2, Appliance setup? For me, it took 10 minutes. If it takes more than 45 minutes, your deployment is probably failing.16. Stage 2 completes. Note that the link assumes you are using DNS. It won’t work unless you have updated your HOSTS or put an entry into your DNS server. Since we are avoiding DNS, lets just say it won’t work.
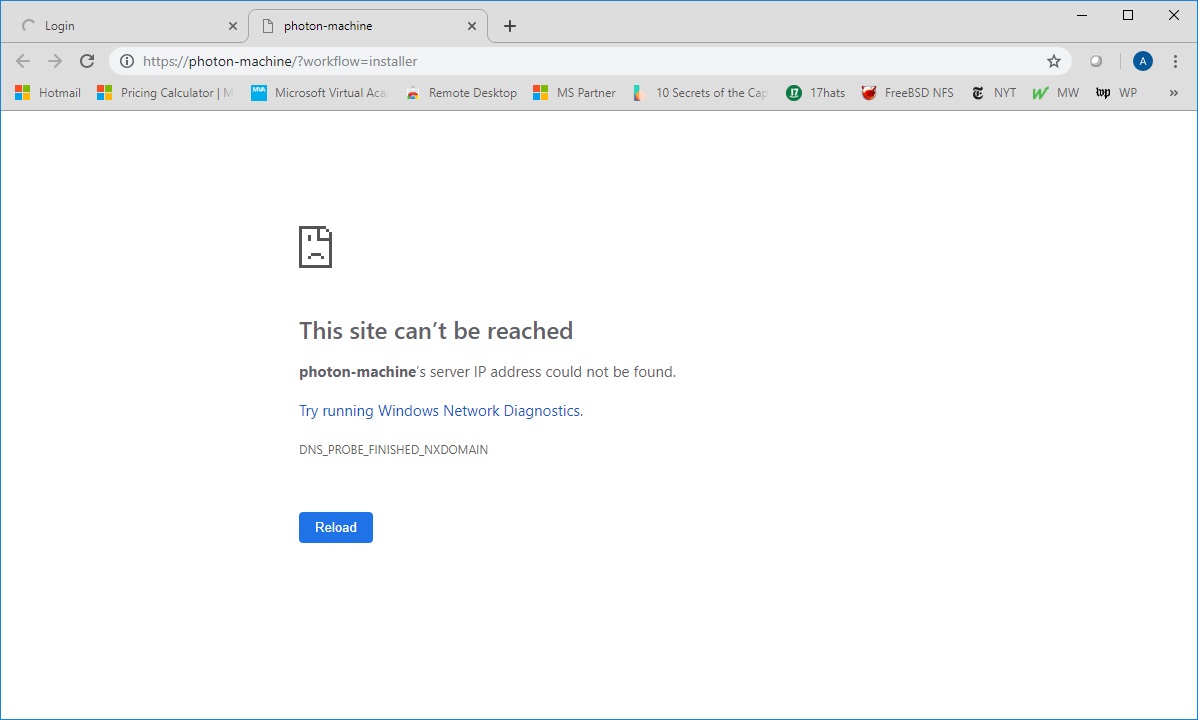
Now to connect to your new vCenter VCSA without DNS..
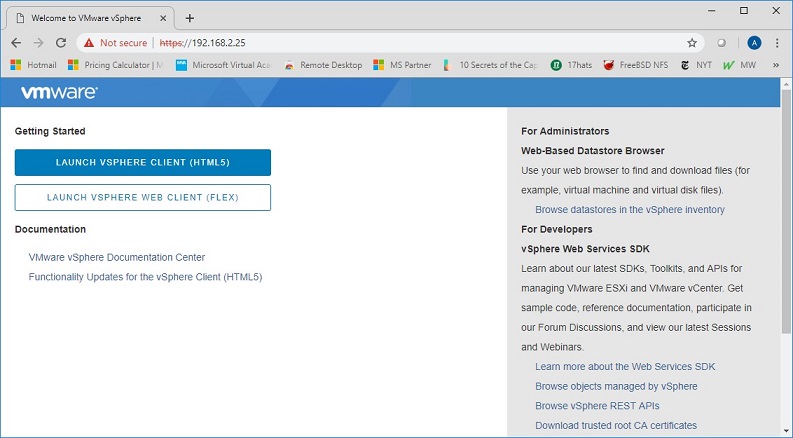
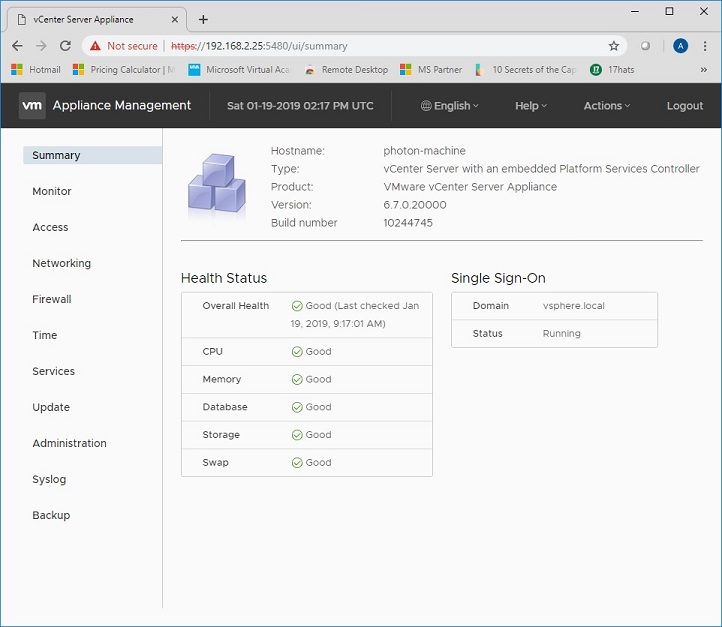
17. As you can see, if you don’t have DNS and just click the link, the page won’t open.18. Change the URL to the IP address of the vCenter server. Now the page displays.19. If you follow the “Launch vSphere client HTML5” link, or simply enter the URL https://vCenter_IP/vsphere-client , the vCenter logon page will display.20. Enter administrator@vsphere.local and the password you set in Step 13. Make sure you have Flash enabled on your browser.21. The vCenter page will open successfully with no DNS.22. How to access the VCSA appliance to perform management functions? Use the URL https://vCenter_IP:5480 and log on with root and the password you set in Step 8.23. Here is the management website for the VCSA
Selfish plug time (sorry!)
Thanks for reading this article! I hope it helps you! If you have tips or feedback, please comment or send me an email so that others can benefit. I am a consultant in the Maryland/DC area in the USA. My specialties are Windows migrations (to 2016 and to Office 365 / Azure), VMware migrations, Netapp and SAN, and high availability / disaster recovery planning. If you would like help with your complex project, or would like a architectural review to improve your availability, please reach out! More information and contact can be found on the About page. – Amira Armond
You are looking for a free Cybersecurity Incident Response Template and getting frustrated because all the other websites want you to register on an email spam list. Or their templates are in PDF format and you’d have to re-write them from scratch. Annoying! I think you will be happy with my template – no registration required, and the template can be downloaded in a Word doc or copy-and-paste directly off this page.
You might have also arrived here looking for incident scenarios that you can use to train your team. At this time, I have 34 scenarios which have an initial incident and follow-up questions to make you consider secondary impacts and problems.
If you are building an incident response policy or procedures for your organization, you will probably want to read the entire article. I give definitions and examples of incident responses, and describe the procedures and tools you should have ready. Finally, at the end, I walk through the template and give information about why each question is asked and the type of answers you should provide.
You may use these incident response templates and scenarios internal to your business and teams. Please do not claim ownership, re-publish this material to the public, or sell it. All text is original work by Kieri Solutions LLC: V. Amira Armond.
Incident Response is the operations part of Cybersecurity. It is about responding to problems in real time. In a lot of ways, an incident is like a helpdesk call. There is some trigger, such as a user complaining about strange network behavior or an automated alert from the security system. The cybersecurity technician starts a process to record the symptoms and gather information. If it is a routine concern, the technician would coordinate a fix, document it, and close the incident. If the problem is serious, or could be serious, the technician would escalate the problem through predefined steps to get the right people involved.
Example of a routine incident (in a large company)
Jim checks the daily antivirus report and finds that workstation BOSTON0094 has been infected with a virus. He starts a ticket, copies details into it, establishes a remote connection to the workstation’s network port and puts it into quarantine. Jim performs research and finds that the virus does not have any remote control or data export features, so there is no need to escalate the level of the incident. He then dispatches a local technician to re-image the workstation. The local technician talks to the workstation owner, picks it up, verifies that critical data has been saved, and re-installs the standard company build on it. The workstation is returned to the owner and the ticket is closed.
Example of a serious incident (in a large company)
During routine maintenance of the database server, Jim noticed a new administrator account that had been created a week ago. It didn’t belong to anyone in the database team, and could be a sign of a security breach. He starts a ticket and calls his Chief Information Security Officer (CISO). The CISO evaluates the situation and decides to contact a specialized cyber-crime consultant for assistance. Over the next few days, they find evidence that an attacker had compromised a workstation then moved laterally through the network. The attacker had uploaded 20 TB of sensitive data from the network. Many parties had to get involved: the IT department, the CISO, the CEO, the legal team, the outside cyber-crime consultant, the FBI, the state police, the cyber-insurance company, and the public relations team, to name a few. The incident took several months to resolve, and caused an impact to the company’s reputation and finances.
2. Tools and templates for a cyber security incident
Before an incident, make sure you have these vital tools, templates, and information used during cyber-security incident response:
Cyber-security incident response policy
This document describes the types of incidents that could impact your company, who the responsible parties are, and the steps to take to resolve each type of incident. It should be customized for your company. For example, a federal contractor should address the risk of sensitive schematics being stolen which could impact the security of the United States. Medical facilities should address the risk of Protected Health Information (PHI) data breach, and patient notifications. Etc.
The incident response policy should have an escalation list so that the correct people are engaged. It should also have timelines for response and communication actions. For example, a minor incident may only involve the help desk. A major incident might need to be communicated to the officers of the company, public relations department, legal firm, and outside law enforcement within a few hours of discovery.
The incident response policy should also discuss procedures for isolating compromised systems, recording evidence, and maintaining a clear chain-of-custody.
Business Continuity Plan (BCP) or Disaster Recovery Plan (DRP)
The BCP or DRP may be utilized during an incident, especially if the incident causes an outage or requires restoration of services. For example, if a server is infected with ransomware, you will need to: 1) Rebuild or fail-over services. 2) Restore from backup. If all of your servers are infected with ransomware, like what happened to the City of Atlanta in early 2018, then the level of complexity goes up.
You want to have a printed-out plan with procedures, configurations, and recovery materials ready to go. Remember, you might need to perform recovery when your servers have been ransomware’d, when the building is flooded, or when power is completely out. Your recovery materials should be stored together in a bundle and you should have a second full copy off-site.
Remember that incidents are not just hackers and viruses. A cyber incident could also be an approaching hurricane, a failed hardware device, or a power outage.
As part of your backups, you should have saved configuration files for each of your routers, firewalls, switches, and other network devices. There are a few reasons for this. If a network device fails, you can normally get a replacement within a few hours. If you have a saved configuration file, you just upload it and go. If not, you might be stuck troubleshooting VPNs, firewall rules, and VLANs, and changing settings as your users complain. Not a good situation. Having time-stamped configuration files also helps during forensics and incident investigation – if you see a strange rule (such as a new connection to a foreign country’s IP) – it would be helpful to find out how long ago the rule was added, and whether it was one of your technicians or an unknown source.
You should also have baseline configurations saved for your user workstations. At a high level, this means having a list of software that has been approved for use on the network. At a granular level, this means running scripts occasionally to pull a list of all software installed, hardware devices, firmware versions, and drivers.
Ideally, as part of your defensive posture, your organization should routinely check for changes in the baselines. A new software program on one workstation could indicate spyware. Changes to firewall rules could indicate an internal threat.
Ticketing system
You should have a timestamped ticketing system, or at least a way for multiple people to record data about complex computer issues. This helps organizations keep track of complex problems without losing them or forgetting who is assigned what task. This removes a lot of second-guessing during investigations since each entry is time-stamped and marked with the author’s name.
Many intrusion detection systems include ticketing capabilities. One example is AlienVault.
Event Logs
Before an incident occurs, make sure you are gathering audit logs. Because attackers sometimes destroy logs to hide evidence, your logs should be sent to a central log (also known as syslog) aggregation system in near real-time. Examples of these systems are Splunk, AlienVault, and VMWare Log Insight. Ideally, this log system will be firewalled from the rest of the network and only a few very trusted people have access to it. Each of your servers and network devices should be set to forward event logs to this device. Almost every operating system and network device in use today has an option to send “syslogs” to another server.
Incident Response Templates
These templates help remind organizations to gather additional information about security incidents. They also include a workflow, which should match the company’s Cybersecurity Incident Response Policy. Make sure to download and customize your incident response templates BEFORE an incident.
How can you prepare your team for an incident?
The best way to prepare is to run regular incident response drills. I recommend the following schedule:
Weekly:
Informal IT-department round table to discuss a random incident scenario and discover gaps or concerns.
Monthly:
Perform a test restore of at least one system.
Quarterly:
Technical review of procedures and policies for accuracy.
Verify contacts list is still valid and contract numbers / policies / warranties are good.
Half-year:
Tabletop drill that follows a complex scenario through to the end. Each escalation point is expected to participate in the drill.
Perform a disaster recovery fail-over and fail-back, or relocation drill.
What is an informal round table?
An example would be the IT manager randomly selecting scenario #4 from this document:
4. A man from “Linux” walks past the reception desk and searches for a open network port to plug his laptop into. What security procedures are in place to prevent him from accessing your network?
During the weekly team meeting, the manager reads this scenario to her team. There is a 5-10 minute discussion about the topic. An IT department might come up with the following gaps:
They have seen unannounced salespeople make it all the way to back offices in the past. There should be a procedure for the receptionist to record visitor IDs and have someone escort them.
There are network ports in all offices which provide DHCP and LAN access to any device plugged in. The corporate switches have the ability to perform MAC filtering, automatic VLAN quarantining, and logically turn off ports, but they are not configured for this yet. The department starts a project to enable these security configurations.
The server room door is near the front desk and is normally propped open due to ventilation issues. The CISO puts in a call to get the ventilation problems fixed so that the server room door can be secured.
Obviously, coming up with three new security projects each week will crush most IT departments. The CISO needs to prioritize by efficiency. Over time, this brainstorm process will greatly improve cyber security for an organization.
What does a test restore involve?
Here is a little known fact about IT: Sometimes backups say they are successful, but when you try to restore from them, the backups don’t work. What the heck!!
This actually isn’t rare. It happens a lot.
You should never assume that your backups work unless you’ve successfully restored from them.
Backups are most likely to fail on database servers. This is because databases normally have multiple files in use, which need to be perfectly synchronized to each other. Without special configuration, backups will copy the first file, then copy the second file, then the third, etc. The files don’t match each other in the backup because they were copied at different times (even half a second will break their synchronization). Pro tip: Use the database’s embedded backup program to create backups to a file on the server, then back up that file.
The restore process can also be a huge problem if not properly prepared for. For example, if you try to restore an operating system backup to different hardware, it will almost always crash because the motherboard hardware and CPU are different. You will either need to remove hardware-specific drivers during the restore process or you will need to have the materials ready to install the operating system and programs separately. It is good to know what to expect beforehand. BIOS boot settings for UEFI versus GPT are another big problem when restoring servers. Make a note of which one you are currently using so that you can pick it correctly during the restore.
And there are always little gotchas. Like your restore process uses a DVD but your servers don’t have DVD drives. Without actually trying to perform a test restore, you won’t catch the little problems.
If you are not careful, your test restore could overwrite your real server, or it could disrupt services by putting a second, conflicting, server on the network. Be careful. Choose your recovery target carefully and isolate the restored server by disconnecting the network. If you plan well, there should be no risk of impact.
What is a technical review of procedures?
Even for experienced technical writers and engineers, it is REALLY hard to capture every step in a procedure on the first try.
So the document might be wrong to start with, or it might address scenario A well, but not scenario B.
Over time, changes to the environment will also make procedures incorrect. For example, an update of the backup software might change the menu options or add more steps to the recovery wizard.
The best way to handle this is to have your procedures document open when you are drilling an incident response or restore, and make a note whenever a step is wrong. Then follow-up regularly to update the main document and send it to the team.
What do you mean, verify contacts and contract numbers?
Your organization should have someone who is responsible for vendor support contracts and escalation contacts. These contacts should include the following:
How to reach corporate officers during an emergency (cell phones, home addresses, etc)
Internal POCs for each department, especially compliance, public relations, and IT.
Local police non-emergency #
FBI cyber-crime reporting #
State cyber-crime reporting #
HIPAA, GDPR, PCI, and other regulatory contacts (if applicable)
Cyber-security consultant on retainer (if applicable)
Law firm on retainer (if applicable)
General insurance for fire, natural disaster, etc (include policy #s, info, limits)
Cyber insurance for data loss, cybersecurity incidents, liability (include policy #s, info, limits)
Data center POCs
Branch office POCs
IT system vendors and support contracts (include warranties, contract #s, and how to start a support call)
The best way to verify that a contact works is to CONTACT them. Put in a help-desk call, talk to the receptionist at the law office, etc. For the crime reporting numbers, regularly check their official websites for changes.
What is a tabletop drill?
Tabletop drills are where you get the PEOPLE and the PROCEDURES together to work through a detailed scenario, but you make no changes to the network or systems.
You want to test each person for responsiveness and to see whether they know their role. You want to test your procedures to make sure they are helpful and don’t have obvious gaps.
A non-participant should organize the drill, take notes, and record the time of each action. Every attempt should be taken to make this drill realistic from a logical point of view.
For example, the organizer might call in to the help desk to report “their computer is acting strangely” – and that this is a drill. They would note how long it took for a technician to diagnose the “problem” and escalate to the security team. They could ask whether the computer has a working antivirus, whether it was recently scanned by the intrusion detection system, or whether the baseline has changed.
As the tabletop drill progresses, the organizer would watch to see if anyone ‘drops the ball’ or fails to escalate properly. They want each person to test normal communication methods for this drill – for example, if the security POC is on vacation, would they call her cell? Do they have the ability to notify customers of an outage? Will the cyber-security consultant answer within an hour? They also want to see how people use procedures and policy during the drill. Did someone use an out-of-date document? Did the procedures tell them to do something stupid? Did the person bypass policy? Pro tip: If you are pulled into a tabletop drill, it is hard to go wrong if you follow the relevant policies and procedures documents.
After the tabletop drill, there are normally many lessons learned and improvements identified. By doing these drills regularly, the entire organization prepares to handle major incidents.
What is a fail-over?
Failing over means moving your organization’s critical services to a different system and/or location. It is similar to testing a restore, but is “for real” – your users are using the services after they are moved.
Done right, there is almost no impact to users. A good fail-over should let an IT department sleep easy knowing that catastrophes will not hurt the organization.
Done wrong, a fail-over can take down critical services. For this reason, testing a fail-over should be done after-hours and system checks should be performed before-and-after to verify that the system is ready for use.
Not every organization can fail over. It requires a large investment to purchase secondary systems and engineer the replication scripts. If you don’t have this capability, then perform the next best thing: test your ability to relocate.
What is a relocation drill?
This drill tests your ability to continue operations after a natural disaster, power outage, fire, or similar event. It can be as high-tech or low-tech as needed. Generally, you won’t be able to perform these actions for real, because your users would be impacted, but you want to simulate the real experience as much as possible.
Here is an example of a medium size business doing a relocation drill: Scenario chosen: Category 5 hurricane causes massive flooding of corporate office. It will be unsuitable for human habitation for at least two months.
The IT department follows their business continuity plan. They have a goal of restoring the 3 most critical services within 12 hours. The IT department contacts their contingency location (another company in a nearby state) and loads spare network equipment and backup drives into a truck. They drive to the contingency location, verify access, and set up their equipment. Network configuration, loading software onto systems, and restoring backups is next. Then they test the ability of a ‘regular user’ to follow instructions to connect to the new servers.
Pro tip: The trickiest part about recovering to a new site is re-routing the network. Everything will be trying to reach the servers at their old network addresses and will get no response. There are three main ways to handle this problem. 1) Your backup vendor may include a proxy ability. For example, Datto backup devices will create a tunnel to the recovered server, listen on-behalf-of’ a recovered server and forward communications to it. For this to work, the Datto device needs to be connected to the original server’s network. 2) Through good network architecture, you might have a very robust DNS and load balancer infrastructure in place. If this is set up, then you just need to update DNS with the new IP addresses. 3) Manual re-route. You may need to edit configurations, re-connect servers to each other, modify group policy, and have your users access a different file share or VPN. Not the best option but this is the most common one.
I guarantee that whenever an IT department does a drill like this, they will learn a lot about what to do, and what not to do. You might find that it is worth the expense to stage more servers at a contingency location, rather than take the risk of not being able to buy new servers during a disaster.
Note: I know of an organization that had a data center in New Orleans during Katrina. It took them a month to restore critical services in a different state. It took them more than a year to get their data center back in New Orleans. This scenario really happens.
———————————-
3. Free Incident Response Threat Scenarios, Questions, and Training Drills
Favorite this page so you can practice scenarios weekly with your team. More scenarios will be added over time.
The first hard drive on your database server failed three days ago. The second hard drive will fail today. Would your staff have found and replaced the first drive before today? Would you have data loss if not? How would you handle the hardware replacement? How would you recover from data loss?
The UPS in your main rack fails and all servers in that rack go offline. How long would it take to respond? How would you restore power? How would you verify that services are functional?
A lady from “Microsoft” comes to the reception desk and asks for directions to the server room. What security procedures are in place to prevent her from physically accessing your servers?
A man from “Linux” walks past the reception desk and searches for a open network port to plug his laptop into. What security procedures are in place to prevent him from accessing your network?
A user from operations mistakes the corporate file share for their personal files, and deletes everything they are allowed to delete. Did they have too much access? What server(s) were involved? How long would it take to recover?
One of your IT staff (pick randomly) uses a terrible password for all of their administrator accounts. “P@ssw0rd1!” is their favorite. Any combinations of “admin” “root” “administrator” “system” and this password will be compromised. Were any systems compromised? Does any system use well-known admin passwords like blank, default, “admin”, “password”, “Pa$$w0rd1!”, “123456”, or “1qaz@WSX1qaz@WSX”? Does your team have a procedure to make sure that terrible passwords are not used?
Pick a user who left the company between 3 and 6 months ago who had remote access. They will decide to access the corporate network using VPN or terminal services today. Will they succeed? Are all of their accounts disabled properly? Does your department have a procedure for regularly reviewing user accounts?
A criminal hacker will attempt to access your corporate network VPN using ports visible from the Internet. Over the next two days, using a script, they will try 20000 user name combinations (jsmith , smith, johnsmith) with the common password “Baseball1!”. Will they succeed? Would your department be alerted about this activity, or would they have to discover it using manual reviews? If manual, would your department detect this activity within a day?
A category 5 hurricane is pointed directly toward your city. Waterways and low lying areas are expected to flood at 10 feet above normal water level. All non-essential staff are expected to stay at home for at least three days. Will your building flood? Is the building going to be totally dark with no power? What electronics and networking would be affected? Would anyone stay in the building to try to handle damage? Would you shut down and physically move equipment to higher ground? What would happen if the roof and windows leaked? Would you implement a disaster recovery plan ahead of time, or wait to see what happens?
A category 5 hurricane is pointed 200 miles north of you. On the day of landfall, it takes a hard left and impacts your city unexpectedly. (If you are not prone to hurricanes, use an earthquake as an alternate.) The power is out for three days X each mile from a power substation (if your nearest substation is next door, your power never goes out. If your nearest substation is two miles away, your power goes out for 6 days). If you don’t know where the substation is, your power is out for 9 days). Do you have generators? Can you get fuel delivered to last the full amount of time? Would your company implement the business continuity plan?
Ransomware just infected every Windows 2008, 2008 R2, 2003, 2000 server, every Windows ME, XP, 7 workstation, and every Linux server running SMB. The devices were not infected if they were 1) unplugged from the network, or 2) un-routable from the workstation LANs. What services went down? Do you have backups for critical systems? Were your backups on SMB shares (and thus, got destroyed too?) How would you recover?
One power supply on your file server went bad a week ago. It shows a red light in the rear of the rack, and an amber light in the front. The lead/manager for the IT department is in the hospital and cannot help. Would your team have detected the power supply failure? How would they get a replacement?
Your database server is filling up its main hard drive with an out-of-control log. It hit 85% full this morning, and will fill up the drive and crash the server in three days. Would your department have caught the disk space issue before the server crashed?
One of your human resources employees lost their company-issued laptop while traveling. Was any PII or PHI on the laptop? Was the data encrypted? Would a technically-competent criminal be able to break into the encryption (for example, the password was written on it)? Could the laptop be used to access the company network? How would you disable the access?
The CEO lost her mobile phone while shopping. It is presumed stolen, and was possibly a targeted attack by a competitor. Would a technically-competent criminal be able to break into the phone to read emails and downloaded files? Could you disable or wipe the phone remotely?
One of your servers suddenly went offline, causing a major outage. Looking at the logs, you see “root logged on” “root initiated a shutdown”. Does your department follow best practices for password management? 1) Each individual has their OWN, NAMED, account. 2) root / admin passwords are complex and stored in a safe. 3) any access to root/admin passwords is logged and the passwords are changed afterward.
Your inbound mail server suddenly started getting millions of emails. It is a distributed denial of service. How would you contain this attack?
Google @yourcompany.com . What email addresses are publicly available on the web? Is there enough information there to perform a spear phishing attack? For example, company directories with names, titles, department, phone number, and email addresses are a major vulnerability.
Your most legacy web server has been compromised. It is now hosting websites in a foreign language and is probably serving malware. Is your most legacy web server fully patched? Is it using any default usernames or passwords? How would you restore it? Assuming that an administrative password was cracked, could you change all admin passwords without breaking anything? Are there open ports from your legacy web server into the rest of the network? How could you secure these better?
Your payments database has been breached. Who would you report it to, and what are the time requirements? Do you have lawyers and public relations staff ready for this type of incident? Check your ability to communicate with internal escalations, external escalations, and end-users.
One of your users will attempt to install DropBox on their corporate workstation and copy sensitive documents (including PHI) into their personal cloud storage. Is the installation prevented at the workstation? Do your firewalls prevent file transfer? Do you have data loss protection programs to detect and block PHI? If the user performs these actions while working through a VPN, would differences in security allow it?
Your company will experience a Business Email Compromise today. An accountant will get an email from the CFO asking for the bank logon and password. Has your accounting department been trained on Business Email Compromise? Do they have a procedure to call or verify in-person before sending very sensitive information electronically? Do you have annual cyber security trainingfor all staff that addresses BEC and other threats?
Your newest IT department member wants to install software that hasn’t been purchased legally. Does your department have a policy against this? Is it part of annual or on-boarding training for your IT staff? Does your company perform audits to find and remove unexpected software?
One of your user workstations has been compromised with remote control software. An attacker is trying to get into other systems by brute forcing passwords. As a result, common account names (default admin and root accounts as well as publicly-known email addresses) are being locked out across multiple systems. Do you have a procedure in place to see these failed logon attempts and lockouts in the logs? Do the accounts lock out permanently, never lock-out, or unlock automatically? (the most secure option is to lock out permanently, but many admin and root accounts should never lock because that would cause an outage too).
One of your DMZ servers has been compromised and an attacker is using it as their base of operations. The attacker is deleting all the Windows logs. If a normal administrator logged on and saw that logs were empty, would they consider it an incident? Are the logs being sent to a central aggregation system? Do you have a procedure to check if servers are sending the normal amount of logs to this system over time? Can you access historic logs from the last year on the central aggregation system, or from other sources?
Your oldest linux server is going to crash today. You will need to restore from backup, or re-build it. Do you have instructions? Do you have the software? Do you have backups? Do you have vendor support for the hardware? Do you have vendor support for the software? Have you ever done a successful test restore?
Your primary router to the Internet crashed because a hacker sent it malformed packets. How would you reset it, and how long would this take? If it continued to be attacked (crashing each time), how would you re-establish Internet services for your organization?
Your administrator workstation was infected with a Remote Access Trojan 7 days ago without your knowledge. Does your admin workstation have ALLOW-ALL rules for outbound communications to the Internet across the firewall? During the last 7 days, did you log on with a domain administrator account or a root account that has privileges to the network, or do you have a “user” account and an “admin” account (this is more secure)? Do you have an intrusion detection agent installed on your workstation that might detect unusual network, hard drive, or process activity? When was the last time anyone checked the results from that agent? Are powershell scripts executed by your computer logged or monitored?
Your company was compromised by a hacker – but worse, they attacked one of your customers using your IT network. Now your customer is suing you for damages. Do you have a cyber liability policy? Would it cover this scenario?
Some of your servers were attacked by malware. As a result, your company lost about $1 million. The forensics review found that the malware was originally developed by “North Korea state agents”, but it is unclear who the intermediate actors were. Will your insurance company consider this an “act of war” and refuse to pay?
Your company was the subject of a data breach of 200 people’s worth of sensitive data (such as SSNs and account info). Think of the three most likely reasons that this scenario could have happened. For example, is it easy to accidentally send an email with sensitive data to the wrong recipient? Are computers with sensitive data in a place where they could be stolen? What could be done easily to reduce these risks?
Your company was the subject of a data breach of 200 people’s worth of sensitive data (such as SSNs and account info). One of your employees had it in an un-encrypted form (such as a printout, thumb drive, on their laptop, or on a CD. What policies and technical safeguards do you have in place to prevent this from happening? Do you have insurance to cover this data breach? What regulations do you need to follow to disclose the data breach? Do you have an incident response policy for data breaches?
(If your company uses OneDrive or another cloud file share service): A critical file on your cloud was deleted two days ago. Can you restore just that file from three days ago? How would you do it?
Your email server’s main disk is filling up with logs. It will grow by 5 GB each day, starting today. If the disk gets below 10 GB free space, your emails stop. Do you have automatic scripts or scheduled checks that will detect the file growth? Will they alert you before you reach 10 GB free? Would your checks have detected the issue before your server stopped?
(Below is a HTML version in case you are worried about opening Word Docs. Try copy-paste into Word, you should be able to capture the table formatting.)
Computer Incident Reporting Form
Is this a drill?
Yes / No
General Incident Information
Date
Incident POC Name
Time
Incident POC Phone
Time Zone
Incident POC Email
Initial Detection
Type of Incident
outage / malware / unauthorized access (outsider) / inappropriate access (insider) / espionage / data breach / other (describe)
Date, time, and time zone of first detection
List names and contact information for all persons involved in detection and initial investigation
How was incident detected?
What do you think happened?
List of systems involved.
Include location, system name, IP address, MAC, serial number, corporate ID.
System 1:
System 2:
System 3:
Where can supporting information be found?
(location of log files, time-stamps, screenshots, photographs, etc)
Could sensitive information have been accessed? Describe worst and best-case scenarios based on current knowledge.
If yes, notify compliance officer, CISO, or another corporate officer immediately. Who was notified? When?
Initial Response
Were any immediate changes made in response to the incident? (such as disconnecting system or disabling accounts).
List time stamps for each change.
Who authorized the changes?
Chain of Custody
Were original systems isolated for forensic review?
Were backups or other system-state copies created? Describe. When were they created?
Location of systems or copies
How are systems or copies protected from alteration?
List name and contact information for person who is responsible for safekeeping of systems or copies
Data Breach Incident
Refer to organization’s data breach procedures or policy. Name of document used:
Each day during incident, add any new findings about worst-case and best-case scenarios for the data breach. Do not delete prior days information.
# of persons affected
List categories of data compromised (names, socials, credit card numbers, passwords, schematics for X design, etc)
Was data copied outside of the organization?
What sources of data were compromised?
Each day during incident, add any escalations or notifications that were performed.
(law enforcement) contacted on date/time
Notified ### customers of potential data breach on date/time
Incident Wrap-up
Current status of incident?
Final root cause analysis
Date, time, and time-zone that incident started
Date, time, and time-zone that incident ended
Describe actions taken to resolve incident (if applicable). Who performed?
Describe containment and/or preventative actions (if applicable). Who performed?
Follow-up actions needed?
List responsible party.
Lessons learned?
———————————-
5. FAQs about the template
Why the emphasis on escalation and recording when you first contacted someone?
If the compromise involved someone else’s data, equipment, or services, your organization is responsible for notifying them.
This statement is confusing to most people. How could a compromise of MY network involve someone else? Here are some examples:
Your web server was compromised and an attacker downloaded all log files. These log files included credit card numbers and user registration for 30,000 customers. Your organization will need to notify credit card companies and the 30,000 customers about the breach.
A human resources database was exported. Each of your employees are exposed to identity theft risk. Your organization will need to warn the current AND past employees about this breach.
Your organization is a web hosting company. You found root access to several servers was compromised. These servers host 1,000+ websites that belong to about 500 customers. A hacker could have used the websites to spread malware, steal account usernames and passwords, modify billing data, or do other mayhem. After you notify your 500 customers, they might need to notify their customers if personal information was stolen.
Your organization suffered a major compromise of almost all systems. Since your suppliers have network connections to monitor your inventory in real-time, they may have been compromised as well. You need to notify the other organizations, as well as any individuals who may have been affected.
Finally, in all of these examples, your organization will probably need to announce the breach to their shareholders, to law enforcement, and to insurance companies.
Most countries have consumer protection laws regarding protection of personal information, financial accounts, and credit card information. These laws regulate that organizations MUST notify individuals if there has been a data breach or suspected data breach. Depending on the type of data involved, there are different requirements for how long a notification can be delayed.
Depending on the type of breach, you might have only 3 days to notify end-users. This means that your initial detection team may only have a few hours to start the escalation process so that your company can investigate, determine the full degree of breach, and start notifications.
What is chain of custody?
Chain of custody is a law enforcement term for making sure that evidence is kept acceptable for court.
In traditional terms, if a bullet casing was found at a crime, an officer would take a picture and place it into an evidence bag with as little disturbance as possible. The bag would be sealed, labeled with the crime, date, time, location. It would be kept in a secure facility with logs to show who accessed it and why.
In court, if you present evidence that hasn’t gone through this safeguarding process, the defense will say that the evidence has been tampered with or even planted. This could make it impossible to prosecute a criminal who has done damage to your organization. So it is important to have a process for chain of custody before your incident occurs.
Digital evidence presents unique challenges since it can change simply by being turned on or off.
Why do we create images of the compromised systems?
The act of restoring functionality will often destroy evidence in digital systems. For example, the best practice response to a workstation infected with malware is to re-image the workstation entirely. This removes the risk of a latent infection, but it also erases logs and usage history which could help identify where the malware came from.
Since organizations can’t afford to stop everything for a few weeks while investigating, a common practice is to create images of systems for forensic use then rebuild them to restore functionality.
What is operating memory and why is it important during a compromise?
Operating memory is the data held temporarily in RAM. All programs use RAM to perform processing and to hold information that is accessed often. Some of this information is logged to the hard drive, but most of it just disappears over time as newer data overwrites it.
For example, as you edit an Excel spreadsheet, everything in the spreadsheet and all of your recent changes are stored in RAM. If Excel suddenly crashed before you saved the document to your hard drive, you would still have a copy of your document in RAM until something else overwrites it, or you turn off your computer. If you turn off a device, all operating memory is cleared as the RAM loses electrical current. Opening and closing programs will also rapidly overwrite the data stored in RAM.
It is especially important to capture operating memory for network devices like routers and switches. This is because they usually have very limited long-term storage.
A computer forensics expert can often retrace the actions of a criminal by reviewing the operating memory of a compromised device.
How can you capture operating memory?
The first step is DO NOT TURN OFF THE DEVICE.
The second step is to make as few changes as possible to the device. Don’t open programs or start processes as this may overwrite critical data in memory.
Next, contact a cyber-security forensics expert for help. If you are that expert, you work with hardware and software vendors to use their tools for capturing operating memory. For example, Microsoft operating systems have the option to run a “memory dump”. Cisco devices can perform ‘core dumps’. The techniques are specific to the system.
Why don’t we just shut down all compromised systems?
See the section about why Operating Memory is important. That is about 80% of the answer.
The other reason: shutting down compromised systems tells your attacker that you know about them. They might start erasing evidence, disconnect, or leave town. You need to consider whether it is worth staying online to gather more information, or whether you should stop the damage now.
What is an alternative to shutting down a compromised system?
Many organizations will disconnect the network cable(s) instead of shutting down. It is still possible for an advanced attacker to do damage – they may have put a logic bomb into the system, for example, but this is very rare.
Why does the template ask for worst-case and best-case scenarios?
Imagine this. You see an administrator account on your file server that shouldn’t exist. The best case scenario is that the hacker somehow got access to the file server without touching any other system in your entire network. Best case, they just looked at a few things then decided to log off, eat some twinkies, and change careers to become a priest. Probably not. But maybe.
The worst case scenario is that every system on your entire network has been breached, fully…
Tips, tricks, and missing steps for the VMWare upgrade
Having done several small / medium business upgrades from vCenter and ESXi 5.5 to 6.0 and 6.5 and 6.7, I wanted to share some best practices and lessons learned with the IT community.
About 2-4 hours during the actual upgrade process. Figure one hour to deploy the appliance (no risk, original vCenter is unchanged), then another hour and a half to replace your existing appliance (your original vCenter is shut down). VMWare is very good about this process and will perform many system checks before shutting down your original vCenter. If something goes wrong at this stage, remember you can shut down (power off) the new vCenter and then start your old vCenter and it should recover.
Don’t forget the preliminary research, system checks, and preparation is another 4 hours for a small or medium business (this includes research for vSphere upgrades).
1-2 hours of the preparation is getting the images downloaded, either to your burned DVD or directly from the VMWare website.
——————————–
What is the risk of downtime while upgrading vCenter?
Good news: For small and medium businesses, there is almost no chance of customer impact while upgrading vCenter. Just don’t plan to do other management tasks at the same time. Remember that the hosts will keep running the VMs, the storage, and the virtual networking unchanged even if they can’t reach vCenter. DRS, HA and vMotion will not be available, so you won’t have normal redundancy.
As long as you complete your upgrade in a reasonable amount of time (one evening), you should be fine. What are the odds a host crashes in that 2-4 hour period? Generally extremely low (less than 0.1%) unless you have more than 5 hosts.
If you have 100+ hosts, then your odds of a server randomly crashing during the upgrade gets closer to 5%. But in that case, you should have a team of experts on the job, so you shouldn’t need much help from this lowly blogger <grin>.
——————————–
Can I upgrade vCenter and vSphere remotely?
You can perform this entire process (vCenter and ESX host upgrades) 100% remotely. Make sure you have a plan for what to do if a host doesn’t come back after rebooting. Ideally, you have an Integrated Lights-Out (iLO) module on your servers, which will allow you to restart them or power on/off remotely.
——————————–
Research before migrating or upgrading vCenter
Make sure you have deep-dived into the existing vCenter appliance and each host before starting.
Make sure to get the following configurations:
Existing vCenter IP , verify root username and password (see next topic)
Network basics (internal domain name, subnet mask, gateway, two DNS servers)
Time provider (NTP). Make sure this matches the NTP source your hosts are using! This is a good time to standardize it across your environment.
A ‘free’ IP address on the same subnet as your existing vCenter server. Will be used for a few minutes during the upgrade.
Configure your DNS servers to have a fully-qualified name for vCenter (the old vCenter IP and your new vCenter’s name). For example: vcenter01.company.com . Make sure you can resolve it before you start the upgrade. The vCenter install (particularly new installs) will bomb out if you don’t have good DNS.
——————————–
When you upgrade to vCenter or VMWare 6x, your vSphere Client (the program) will stop working! There is no client download on the website! How can you connect?
History: vCenter and vSphere 6x are designed to be managed with your web browser, using flash. VMware did this because there are all sorts of really niche configuration options that almost no-one uses. Adding the niche options to a website is easy. Adding them to the vSphere client is not. In version 5x, VMware put only basic functionality in the vSphere client and started offering niche options in the management website ( https://hostname:9443/vsphere-client ). In version 6x, VMware got sick of updating both the website and the vSphere client, so they stopped offering the vSphere client program. Nooo!
So now that you’ve upgraded to 6x, how can you connect and manage your virtual environment?
Using Chrome, IE, or Firefox, make sure you have Flash installed. https://get.adobe.com/flashplayer/ (Personally, I use Chrome, so the rest of the instructions will match Chrome.)
Navigate to https://vcenter_server_fqdn/vsphere-client
or for a host.. https://host_ip_address_or_fqdn/vsphere-client
Didn’t connect? Make sure you have a DNS entry for your vCenter server. This is a requirement for 6x
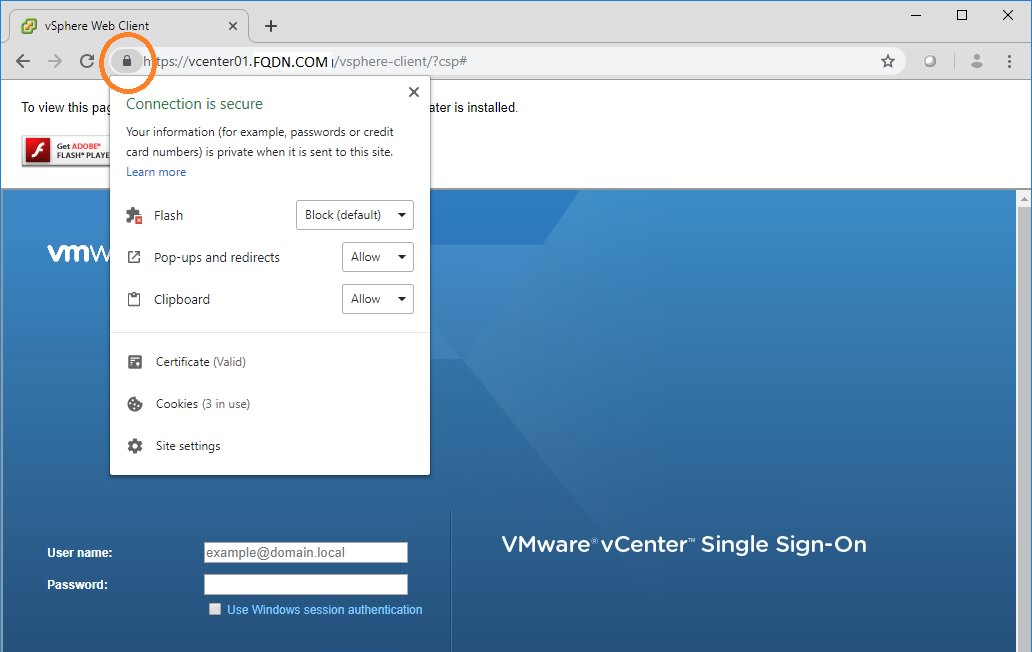
Now you probably have a warning “To view this page ensure that Adobe Flash Player version x or greater is installed”. But you already installed Flash Player! What the heck, Chrome?
You need to enable Flash each time you open the website for the day. Look for the lock icon in the address bar. Click on it and you will see Flash listed as blocked. Change it to Allow.
You will be prompted to Reload the page. Do so. Now flash will work and you can log on. Default username for vCenter “vSphere Web Client”: administrator@vsphere.local . Default username for vSphere (individual host ESXi servers): root. In both cases, you should have been prompted to set the password during install or upgrade.
——————————–
What about opening the Console to a virtual machine?
The console still works, but it now requires you to download a separate program Here is how to open console in 6.0 6.5 and 6.7.
You need to download the “VMware Remote Console” from the VMware website. It can be reached by … Downloads > vSphere > “Drivers & Tools” tab > VMware Remote Console.
Expand VMware Remote Console then click Go To Downloads.
You will see separate installers for Windows (all Windows variants), Macintosh, and Linux systems.
You will need to log on with a VMware account – if you don’t have one already, just go ahead and register for the free account.
Download and install the remote console on your computer. No reboot necessary.
Next time you select “Open Console” from the vSphere / vCenter web client, it should prompt you to open the link with a program. Select the VMRC (Vmware Remote Console).
Your VMRC console should now open and you can interact with the desktop.
When you click Open Console in 6x, a new webpage will open. It attempts to start the VMware Remote Console program and connect it to the guest VM. It is safe to close this window as soon as VMRC is started.
In 2017 and early 2018, the remote console was terrible with jumpy mouse, mouse disappearing, or offset mouse issues. The remote console has since been updated and works very well with all the operating systems I’ve tried (CentOS, Ubuntu, RedHat, Windows Server 2012, Server 2016, etc.
Installing VMware tools on the guest VM will normally help with sync issues.
Remember, if your mouse or keyboard get ‘stuck” in the console session (normally this only happens with pre-boot environments), just press left-CTRL and left-ALT at the same time.
——————————–
Problem: Can’t log onto the old 5.5 vCenter appliance
Symptom: You are pretty sure you know the root password, but it is not working on the web GUI. ( https://vCenterIP:5480 ) It says wrong password.
Symptom: The 5.5 vCenter appliance was built more than a year ago.
Fix: Connect to vCenter using SSH
(I recommend using the Putty SSH application which is available at this link). After connecting, when you enter ‘root’ and the correct password (default is ‘vmware’ but you’ve probably changed it), you will be told that the password is expired. Change the password using the SSH dialogue and now you can log on to the web GUI.
Cause: When you build a vCenter appliance (5.5, 6.0, or 6.5 or 6.7), by default, the system expires the root account after one year. I recommend un-checking this immediately whenever you build vCenter. If you want to change the root password periodically, you can still do it, but this way your department won’t get locked out.
——————————–
How to upgrade vCenter from 5.5 to 6.0 or 6.5
I personally recommend deploying 6.5 vCenter appliances (rather than deploying vCenter onto a Windows server).
The first step to upgrading is to perform a snapshot of your vCenter virtual machine. If you quiesce guest memory and something goes wrong during the upgrade, you can revert to the snapshot and everything will be working again within 5 minutes. This truly can be depended upon. Make a reminder to remove the snapshot after everything is stable.
Stage the upgrade
Note: You will need a valid VMware account. These steps are performed on a Windows 10 administrative workstation.
Adjust the version selection as necessary. Make sure that your vCenter is the same or HIGHER version as your ESXi servers.
Find the VMware vCenter Server Appliance , file type: iso ( about 3-4 GB) and download it.
Mount the ISO by right-click, Open With, Windows Explorer.
The files will appear in your DVD drive letter in Windows Explorer.
Navigate to \vcsa-ui-installer\win32\installer.exe and start it
vCenter appliance installer will display. Click Upgrade.
Here is a helpful video that describes pre-requisites and has step-by-step instructions to perform the upgrade. Text steps continue below.
vCenter Appliance Upgrade Stage 1
Upgrade Stage 1: Deploy Appliance – Introduction displays. Click Next
Upgrade Stage 1: Deploy Appliance – License agreement displays. If you want to proceed, click Accept and Next.
Upgrade Stage 1: Deploy Appliance – Source Appliance displays. Identify your Source Appliance (your existing vCenter 5.5 server) and provide credentials to access it. The default HTTPS port 443 is correct unless your environment has changed it (this is unlikely). The SSO User Name is normally administrator@vsphere.local , but this could be any full administrator account. Appliance (OS) root password refers to the root password for the vCenter 5.5 appliance. The root account can be tested by opening website to the vCenter 5.5 server https://vCenterIP:5480 or connect via SSH to the server.
You have a choice to specify either the ESXi host or vCenter server that manages the source appliance. It is recommended to specify the ESXi host, not the vCenter server, in that box. You can specify by IP or DNS (IP is less likely to have issues).
Click Next
Upgrade Stage 1: Deploy Appliance – .Specify deployment type displays – Embedded Platform Services Controller is appropriate for environments with 1-20 vSphere ESXi servers. If you aren’t sure, and you have less than 20 hosts, go for Embedded. If you have more than that, do some research to see what is best for your environment.
Upgrade Stage 1: Deploy Appliance – Appliance deployment target displays. Enter the ESXi host IP address or DNS that you want to host the new vCenter server. This can be the same ESXi host as is already hosting (make sure you have at least 10 GB of RAM available on it), or a different one. You will need to specify the username and password for the ESXi host.
Upgrade Stage 1: Deploy Appliance – Select folder displays. You can put the new vCenter server into a logical folder in your environment.
Upgrade Stage 1: Deploy Appliance – Select Compute Resource displays. You can choose which ESXi server runs the new vCenter server.
Upgrade Stage 1: Deploy Appliance – Set up target appliance VM displays. You can assign a name to the new vCenter server and give it a root password. Take note of this username and password – you will need it to manage the new vCenter server in the future.
Upgrade Stage 1: Deploy Appliance – Select deployment size displays. Look up the number of VMs you are running in the table, and pick your vCenter size based on it. Most environments qualify for Tiny, with less than 10 hosts.
Upgrade Stage 1: Deploy Appliance – Select datastore displays. Pick a datastore that has space to hold the server size you picked in the last step (Tiny = at least 250 GB free).
Upgrade Stage 1: Deploy Appliance – Configure Network Settings displays. Pick the VM network from the list that is the same as your old vCenter server and assign a temporary IP address on the same subnet as the old vCenter server. Your admin workstation needs to be able to communicate with this IP address as well.
Upgrade Stage 1: Deploy Appliance – Ready to complete stage 1 displays. Click Finish to run the deployment. It should complete Stage 1 in about 30 minutes or less.
Click Continue to proceed to Stage 2
Note: If you get an error communicating with the new vCenter at this point, your workstation is having trouble reaching the new server over the network. Did you assign the VM to the correct virtual switch? Did you give it an IP address that can route on that subnet?
Stage 2 of the vCenter Appliance Upgrade
Upgrade Stage 2: Introduction displays. Click Next
Upgrade Stage 2: Pre-upgrade check result displays. Warnings may display, depending on how your vCenter 5.5 server is configured. Recommended resolutions will also display. You can close the results after reading through them.
Upgrade Stage 2: Select upgrade data displays. I recommend copying everything from the source to the new vCenter, but if you are worried about space, just move the configuration. The events, tasks, and performance metrics are just for audit purposes.
Upgrade Stage 2: Configure CEIP displays. Depending on your company policy, join or do not join VMware’s Customer Experience Improvement Program. Most security conscious businesses or government agencies will not join the CEIP.
Upgrade Stage 2: Ready to complete displays. Click Finish when ready.
Data transfer and setup runs – this will take up to 45 minutes normally. When finished, you can click the Close button to finish the wizard.
Now you can log on to the new vCenter and check it out! https://vCenter_IPaddress/vsphere-client
——————————–
Can I install vCenter without DNS?
YES.
Check out this blog I wrote on how I installed vCenter 6.7 without DNS.
What if you have a Windows-based vCenter appliance?
Especially if you have update manager installed? This can get ugly. The basic steps are to install the vCenter update then install the Update Manager update. But, occasionally, vCenter will start acting really buggy and the client crashes. The good news is that you can roll back to the latest snapshot of vCenter (you did snapshot it with quiesce memory before the upgrade , right?) and it will go back to normal, the bad news is that you probably will need to rebuild vCenter or call VMware if you have a problem.
——————————–
Upgrade fails, need to rebuild vCenter
If your vCenter deployment is a typical medium or small business size, re-building your vCenter from scratch is actually faster than troubleshooting it, and doesn’t involve downtime. 90% of the configuration is held on the hosts, including datastores, virtual switches, and VMs. Make sure to spend 10 minutes looking at your old vCenter and screenshot the following:
License keys
User accounts and any custom permissions
Network settings for vCenter server
NTP settings
HA and DRS settings
CPU compatiblity settings
Keep-away and custom rules settings
If you use distributed switches or other advanced items like NSX and vSAN, rebuild at your own risk. Make sure you’ve really captured the configuration steps before you proceed.
Once you have the config’s captured, just turn off your old vCenter and build a new appliance from scratch. Set up your clusters and licensing, then add each host. Everything should come in correctly. Make sure to re-connect your backup programs to the new vCenter afterward.
Hint: You can install vCenter at 6x directly. No need to install a 5.5 version.
——————————–
How to set password policy so that you don’t get locked out
One of the first things you should do is change the password policy on your vCenter so that the accounts do not expire after 90 days. If you require a password to be complex (meaning 14+ characters long), you shouldn’t need to expire it for years and years.
To view or change the policy:
Log on to vCenter https://vCenterName.domain.etc/vsphere-client with administrator@vsphere.local
From the Home menu (icon looks like a house), select Administration
Under Single Sign On, select Configuration
Select Policies, then Password Policy, then click edit.
To set passwords to never expire, change the Maximum lifetime to 0.
I also recommend increasing the maximum length to 16, reducing the character requirements to 1 each, and limiting the identical adjacent characters to 3.
Click Save to save changes. These changes are global to all _______@vsphere.local accounts.
——————————–
vSphere ESXi upgrades from 5.5 to 6.5 or 6.7
Before you upgrade your ESX hosts, take a quick read through the rest of the topics below. There are lots of good tips and things to avoid.
——————————–
How long does it take to upgrade an ESXi host?
Do you have a shared SAN with 10gbps storage networking??? It is normally about 1.5 hours per host to perform the upgrade.
Are your VMs stored on the local hard drive of the ESXi hosts? It will take # minutes to vMotion the VMs to another host, + 1 hour. In many cases, it is more efficient to power off all VMs and perform the upgrade, then power the VMs back on, if you are using local storage.
You can save time by upgrading multiple hosts at once. This of course requires either powering off the guests or having enough extra resources to host them on the other servers.
Here is the time breakdown I use:
10 minutes: vMotion all guests off the host (this assumes you have fast shared storage). Or power-off the guests.
2 minutes: Put the host into maintenance mode
5 minutes: Enable SSH in services. SSH into the host and perform pre-upgrade scripts.
30 minutes: Download and install the latest image from VMware repository (requires Internet)
15 minutes: Reboot the host and wait for the server to load back into the ESXi operating system fully.
20 minutes: Apply SPECRTRE / MELTDOWN setting and reboot again ( only if you haven’t patched in a while).
5 minutes. Disable SSH in services. Take the host out of maintenance mode.
10 minutes: vMotion a non-critical guest to the host and test functionality.
10 minutes: Finish vMotioning other guests to the host (or power on the guests).
——————————–
What is the risk of downtime for ESXi upgrades?
The first question is: Are all your hosts running the same model of hardware?
If YES… then your risk is almost nil.
If NO… your hosts are running different hardware models (such as a Dell R710 and a HP DL360 gen8 and a HP DL360 gen9), then your risk of downtime or customer impact is pretty high. Read through the topic below, “CPU Generation Compatibility Levels” before you continue.
Next question: Do you have enough RAM and disk space to run all your VMs on (HOSTS – 1) ?
Figure this out ahead of time. Many companies have a few high-resource VMs such as database servers, which take up all or most of the resources on a host. Plan how you will migrate the VMs around so that all the VMs will fit onto your other servers. Note: You CAN overallocate RAM on ESXi hosts. They will page the less-used memory to disk. This normally won’t hurt performance much as long as you don’t over-allocate too many resources. Here is a (very) technical article about overallocating memory and CPU on VMware: https://labs.vmware.com/vmtj/memory-overcommitment-in-the-esx-server
If you properly migrate your VMs off each host, putting it into maintenance mode, before upgrade, you should be good. I still recommend doing this portion after-hours so that you minimize impact from vMotion and have the maximum amount of redundancy during the workday in case one of your hosts randomly fails.
——————————–
Problem: When I try to vMotion a guest VM, the option is grayed out?
Normally this issue is because the VM is changing in some way. For example, it might be migrating somewhere already, or you just modified the hardware settings and it is still saving, or you just powered it on, etc. Another possibility is that your Veeam is performing a backup of that VM.
If Veeam backup is occurring (you can tell by looking at the current Snapshots), wait for the Veeam backup to complete, or cancel it.
If a fast task like changing settings is running, wait for it to complete.
If you can’t find the cause, try shutting down the VM and powering it back on. Sometimes that clears the issue. Obviously not the ideal answer.
——————————–
How to upgrade ESXi hosts using command line remotely
For this procedure, you WILL need Internet access from the host. If you have a decent business ISP, it should take less than 20 minutes to download the update.
1. vMotion or power-off all VMs off the host. Note: you may need to disable automatic load balancing in your cluster if the VMs are automatically migrated back.
2. Put the host into Maintenance Mode
3. Start the SSH service on the host ( Configuration > Security Profile > Services > Edit )
4. SSH to the host ( I use the Putty program which is freely available on the internet)
5. Log on as root
6. Perform this command to enable downloads from the VMware Internet repository”
esxcli network firewall ruleset set -e true -r httpClient
7. Determine which version of ESXi you want to update to.
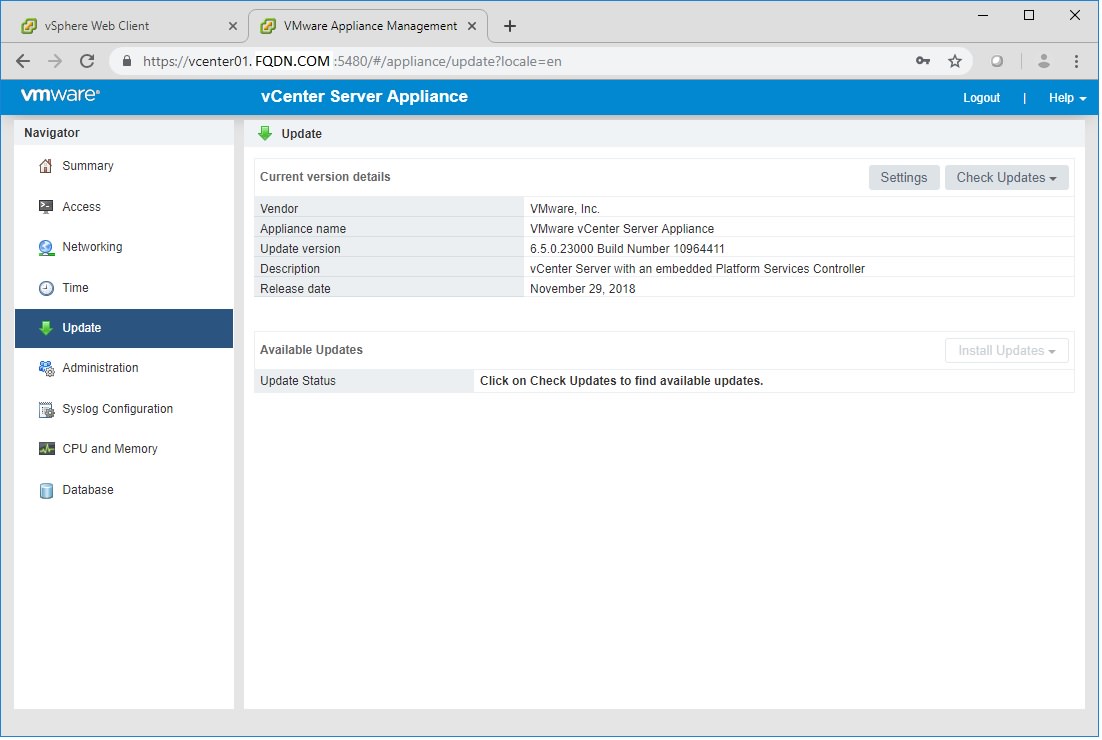
IMPORTANT: Never update your ESXi version higher than your vCenter version!! If you do, your vCenter will disconnect the hosts!!!
For example: When I check my vCenter version in the Appliance website ( https://vcenter.fqdn.com:5480 , update tab), I see my vCenter is version “6.5.0.23000 Build Number 10964411” with a Release date of November 29, 2018.
I look up the VMware patch tableand decide I want to download ESXi 6.5 EP 11 which was released November 9, 2018 and has a slightly lower build number than my vCenter server.
Version
Release Name
Release Date
Build Number
ESXi 6.5 EP 11
ESXi650-201811001
11/09/2018
10719125
Perform this command in SSH to see what versions of ESXi are available from the VMware Internet Repository:
Review the list for the version you want. Copy the package name to your clipboard. The package name will look like ESXi-6.#.#-########-standard
When I perform the query in SSH, I see packages that match the release name:
ESXi-6.5.0-20170304101-standard VMware, Inc. PartnerSupported ESXi-6.5.0-20171201001s-standard VMware, Inc. PartnerSupported ESXi-6.5.0-20170304101-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20181101001s-standard VMware, Inc. PartnerSupported ESXi-6.5.0-20180604001-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20180502001-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20171204001-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20170304001-standard VMware, Inc. PartnerSupported ESXi-6.5.0-20181104001-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-4564106-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20181101001s-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20181103001-no-tools VMware, Inc. PartnerSupported ESXi-6.5.0-20180501001s-standard VMware, Inc. PartnerSupported ESXi-6.5.0-20170304001-no-tools VMware, Inc. PartnerSupported
Since I want the full package including latest VMWare tools, I pick the package named “-standard”.
8. I then run the UPDATE command, adding the package name to it.
After about 5 minutes (depending on your internet connection), you should get a successful message.
Update Result Message: The update completed successfully, but the system needs to be rebooted for the changes to be effective. Reboot Required: true VIBs Installed: VMware_bootbank_esx-base_6.5.0-2.71.10868328,………,………,………,………,………,………,………,………,………
9. Type reboot in SSH to reboot your host.
10. Wait for the reboot to finish. Generally, I just wait for vCenter to show that the host is back online.
11. SSH back into the host, logging on as root. Note: If SSH doesn’t connect, you may need to re-start the SSH service in Security Profile.
12. Disable downloads from the VMware Internet repository by running this command:
esxcli network firewall ruleset set -e false -r httpClient
13. Take the host out of Maintenance Mode
14. vMotion or power-on a non-critical guest VM to this upgraded host.
15. Test functionality of the non-critical VM (especially check the ability to ping it, which is a good all-around test of host, network, and VM)
16. vMotion or power-on the other VMs to the upgraded host.
17. Stop the SSH service on the host (Configuration > Security Profile > Services > Edit )
18. Continue upgrading other hosts.
If you need more information, here is a longer guide for upgrading ESX 5.5 to 6.x using command line by Deflounder.
This is a big concern because if you don’t avoid it in advance, you will have to shut down some VMs in order to complete the ESXi hosts upgrade.
If you have more than one model of server, deep dive on this BEFORE you start upgrading ANY hosts.
Symptoms
You have older hosts mixed in with newer servers.
After upgrading a host to vSphere 6.0 or 6.5, you cannot vMotion your VMs to it. “The virtual machine requires hardware features that are unsupported or disabled on the target host. General incompatibilities. If possible, use a cluster with Enhanced vMotion Compatibility (EVC) enabed, see KB article 1003212.“
Root Cause
vCenter 5.5 seems to handle CPU compatibility without any configuration steps. Later versions need to be configured for this before you turn up hosts.
In vCenter 6.0 and 6.5 and 6.7 , you need to set up a Cluster object and put your hosts into it in order for Enhanced vMotion Compatibility to work across CPU generations. But you can’t do this while your host has any VMs running. If you upgrade then move your VMs onto the host without setting up the cluster object, you will have issues vMotioning the VMs to other hosts later.
Fix: Set up cluster in vCenter, configure CPU compatibility levels to the lowest common denominator, and add your newest host to it early.
After upgrading vCenter, but before upgrading hosts, create a cluster object (right-click the datacenter, New Cluster)
After naming the cluster, right-click it and select Settings.
Select the “VMware EVC” tab in settings. Enable it, and select the lowest (oldest) CPU generation for all of your hosts.
Starting with your newest hosts (the highest generation), move them into this cluster after upgrade but before migrating VMs back onto them.
For example, I will upgrade ESX05 first because it has the highest CPU generation.
(I have already upgraded vCenter to 6.5)
Create a cluster object and configure CPU compatibility at the LOWEST common level
vMotion all VMs off ESX05 to older hosts.
Put ESX05 into maintenance mode in vCenter
Install ESXi 6.5 on this host
Re-add ESX05 to vCenter if needed.
Move ESX05 into the compatibility cluster while it is in maintenance mode with no VMs.
Configure and thoroughly test ESX05 (see topic below).
Take ESX05 out of maintenance mode
vMotion some VMs onto ESX05, in preparation for upgrading ESX04 (the next lower generation server) next.
If you do this right, you should be able to avoid customer impacting downtime.
Problem: Did you miss the CPU compatibility fix and already vMotioned some VMs into an upgraded, newer host?
Sorry. You are stuck with a situation where you can’t get your last host(s) into the compatibility cluster because you have live VMs on it and you can’t vMotion the VMs to any other host. This is not an acceptable stopping point because you lose cluster benefits like DRS and also can’t vMotion for regular maintenance in the future. So bite the bullet and fix it now, rather than wait until you are forced to do it in the future.
If you get stuck in this compatibility hell, then the easiest solution is to shut down all the VMs on that host then move the host into the cluster. This normally results in a downtime of about 10-15 minutes, depending on how fast your VMs boot up.
Problem: Did you upgrade the host with vCenter on it, and now you can’t migrate without shutting down vCenter?
How to fix vCenter vMotion CPU compatibility issue:
Here is the situation. You are trying to vMotion your vCenter to another host, but you get an error about CPU compatibility. Errors like “The virtual machine requires hardware features that are unsupported or disabled on the target host” “If possible, use a cluster with Enhanced vMotion Compatibility (EVC) enabled; see KB article 1003212″ ” CPUID details” “incompatibility at level 0x1 register ‘ecx'”. “FMA3 is unsupported” “MOVBE is unsupported” “RDRAND is unsupported”
The normal fix is to power off the VM momentarily, vMotion it, then power it back on. During power-on, it will use the new host’s CPU capabilities.
But with vCenter, you can’t do this, because you are using vCenter to perform the vMotion, so powering it off means you can’t communicate with both hosts at once.
Shared storage fix:
If you have shared storage (both hosts can reach the same datastore), you can use VMWare’s instructions to fix the problem. Essentially, you make sure the vCenter server is on shared storage, then you connect to each host’s vSphere website directly. Power vCenter off and remove it from inventory (no delete!!!!) on the first host. Then Add vCenter to inventory on the second host and power it on.
No shared storage? Using local disk / datastore for each host?
This is how I’ve fixed it.
Using vCenter, with vCenter powered on, I right-click the existing vCenter server and Clone it to the second host’s datastore. Note: Name the clone something you are happy to use permanently)
Wait for the clone to finish, (the clone will be powered off).
Open the vCenter management website ( https://vcenterURL:5840 ) and log on to it
In another tab, open vSphere website to the second host (that has the clone) and log on to it.
Right-click the clone vCenter and Power On
Immediately Shut Down the original vCenter using the management website.
Wait for about 10 minutes, then attempt to connect to vCenter normally. You should be working from the clone now.
Once you feel comfortable, delete the old vCenter.
Something went wrong?? Rollback instructions:
If the clone vCenter doesn’t work, just shut it down using the second host’s vSphere website.
Connect to the first host’s vSphere website and power on the original vCenter.
You can avoid 99% of the risk by testing your upgraded host thoroughly before you put production VMs onto it.
I recommend the following tests (at minimum)
Make sure you’ve got your upgraded host configured, into vCenter, and into it’s destination cluster.
Using a test VM (build one up if you don’t have one ready), test connecting to each virtual switch and pinging to-and-from other servers across the network.
Storage vMotion the test VM to each major storage system you have.
vMotion (processing) the test VM between your upgraded host and other hosts. Test both directions.
Snapshot and delete snapshot on the test VM.
And before you close this project, make sure to re-connect your backup jobs and test them.
——————————–
Good luck in your upgrade process!
(shameless self promotion) By the way, I consult on VMware, Storage Area Networks (such as Netapp, Synology, FreeNAS), high availability designs, and migrations to the cloud. I offer 30 minutes of free technical advice on these topics: if we can solve your problems in that time, great! If the problem is too big, we can start working on a plan together. Please schedule using the button below! – Amira Armond, President, Kieri Solutions
I recently spent time building FortiAnalyzer reports to let management see which devices are spending the most time browsing non-work websites. I was really surprised how hard it was to find information on this topic. No default reports on the FortiAnalyzer gave the level of detail I wanted without running the User Detailed Browsing Log over and over for each device and scanning through thousands of logs. Ended up writing custom queries and doing it the hard way. My loss is your gain.
There are a few major caveats that I have to go through with you first:
FortiAnalyzer has no way of telling whether traffic logs are generated by a user or by a background process on the device. For example; if you see a device, let’s call it 192.168.100.28, making connections to a botnet in China, it is good odds that malware is doing the talking, not the user.
Without special agents configured, FortiAnalyzer has no way to tell which USER is logged on to a device. If you see 192.168.100.28 connecting to porn websites at night, you may want to verify who was actually sitting at the keyboard before going on a firing spree.
The “Requests” column really refers to the # of traffic logs generated. In my limited review, it seems like a new connect log is generated about once a minute during active browsing. So I use this to distinguish between a quick connect (for example, to download pictures or advertisements on a linked page) and a long browsing session. The custom reports are set to filter single requests, dramatically reducing the number of pages.
The “Bandwidth” column is exactly as it seems. If nothing else, goofing off on social media or YouTube does hog bandwidth from other legitimate users.
In my custom report, I filtered out categories that seem like normal work web browsing or data transmissions to/from vendors: Reference, Information Technology, Search Engines and Portals, Web Hosting, Business, Government and Legal Organizations, Information and Computer Security. I also filtered out Advertising because otherwise it is about half the report, and normally users don’t choose to view advertising on purpose.
Selfish plug time (sorry!)
I hope this article helps you (don’t worry, the next section has the FortiAnalyzer code you are seeking). If you have tips or feedback, please comment or send me an email so that others can benefit. I am a consultant in the Maryland/DC area in the USA. My specialties are Windows migrations (to 2016 and to Office 365 / Azure), VMware migrations, Netapp and SAN, and high availability / disaster recovery planning. If your business would like help with your complex project, or would like a architectural review to improve your availability, please reach out! More information and contact can be found on the About page. – Amira Armond
How to create the first custom FortiAnalyzer report “ALL USERS BY CATEGORY”:
Note: The code works well on FortiAnalyzer 5.4.3. If you have syntax problems on other versions, review the “Top Web Users by Allowed Requests” dataset to verify your table and column names.
Create a new dataset named “ALL USERS BY CATEGORY”
Log type = Traffic Query = select sum(minutes) as CountTimeStamps, user_src, catdesc, hostname as website, status, sum(bandwidth) as bandwidth from ###(select count(dtime) as minutes, coalesce(nullifna(`user`), nullifna(`unauthuser`), ipstr(`srcip`)) as user_src, catdesc, hostname, cast(utmaction as text) as status, sum(coalesce(sentbyte, 0)+coalesce(rcvdbyte, 0)) as bandwidth from $log-traffic where $filter and hostname is not null and logid_to_int(logid) not in (4, 7, 14) and (countweb>0 or ((logver is null or logver<52) and (hostname is not null or utmevent in (‘webfilter’, ‘banned-word’, ‘web-content’, ‘command-block’, ‘script-filter’)))) group by user_src, catdesc, hostname, utmaction)### t group by user_src, catdesc, website, status having sum(minutes) > 1 order by catdesc, CountTimeStamps DESC Apply…
Create a new Chart named “ALL USERS BY CATEGORY”
Select dataset = ALL USERS BY CATEGORY
Resolve hostname = Inherit
Chart type = table
(The columns should auto-populate)
Change counttimestamps to “Requests (minutes”) and width = 5%
Change user_src to “User/Source” and width = 14%
Change catdesc to “Category” and width = 20%
Change website to “Website” and width = 0%
Change bandwidth to “Bandwidth” and width = 6% and change the binding for this field to “Bandwidth (KB/MB/GB”
Order by = unchecked
Show Top (0 for all results) = 0 **Double check this one**
Apply…
Create a new report:
Create from Blank, named “ALL USERS BY CATEGORY” Go to Layout tab > Insert Chart >
Select the ALL USERS BY CATEGORY chart.
Title = Default
Width = 700
Filters = (Click + to add a filter)
Log Field = Category Description (catdesc)
Match Criteria = Not Equal To
Value = type “Advertising” and press Enter. Now add the rest of the categories, pressing enter between each one.
Advertising
Reference
Information Technology
Search Engines and Portals
Web Hosting
Business
Government and Legal Organizations
Information and Computer Security
Apply and run the report using the last 10 hours or so. You should get something like the picture at the top of this blog. Note: If you have more than 10,000 lines in the report, it will cut off. Report across fewer hours if this happens.
How to create the second custom report “ALL USERS BY USER ACTIVITY”:
Note: The code works well on FortiAnalyzer 5.4.3. If you have syntax problems on other versions…