

vSphere Health detected new issues in your environment 6.7
Symptom: You start seeing the alarm “vSphere Health detected new issues in your environment” and it won’t go away.
I wrote about this alarm with one cause: Memory Exhaustion with a Tiny deployment in my other blog. If you navigate to your vCenter appliance website (https://vcenter.company.com:5480) and see memory warnings, check the fix in that blog first.
Symptom: You recently upgraded to vCenter or vSphere ESXi 6.7 U2 (Update 2, April 2019, May 2019)
Symptom: Warning in event logs “Alarm ‘vSphere Health detected new issues in your environment’ on Datacenters changed from Green to Yellow”
Symptom: Warning in event logs: “event.vsphere.online.health.alarm.event.fullFormat (vsphere.online.health.alarm.event)
Symptom: You don’t see anything to explain the issue in the logs. Looks like a false positive?
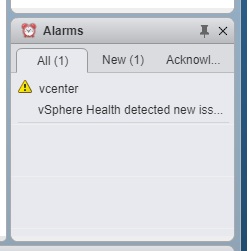
Symptom: When you navigate to vCenter > Monitor > Health, there is no health tab.
This is the main symptom for this particular issue. Read on!
Root Cause #1: You are still using the Flash vSphere client from version 6.0 and 6.5.
You need to change the URL you are using for vSphere and vCenter: https://vCenter.company.com/ui
You can find this URL from scratch by navigating directly to your vCenter: https://vCenter.company.com and clicking the HTML5 button
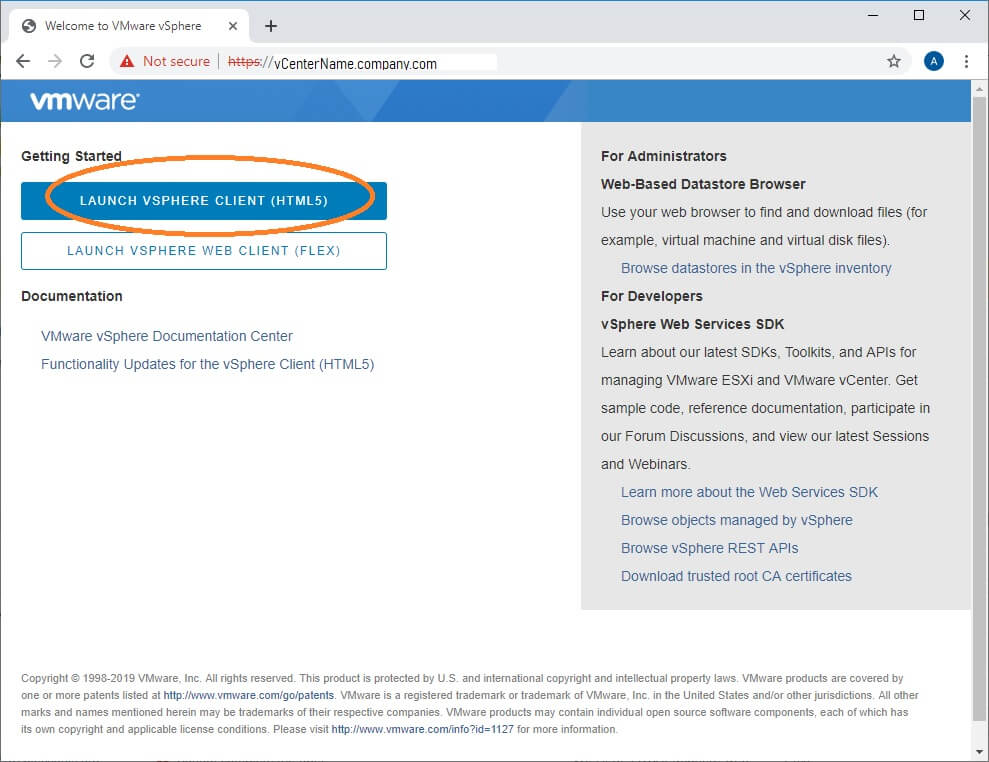
You can also find it right at the top of your vSphere website – Look for a button that says “Launch vSphere Client (HTML5)”
Now that you’ve launched the HTML5 site, you will notice that it looks way different!
Root Cause #2: The latest updates for vCenter and vSphere include new checks for common issues.
The April 2019 and May 2019 release of 6.7 Update 2 include new health checks. Your vCenter will now warn you about things like problematic drivers and known memory leaks.
These checks are only visible in the HTML5 client. This is why you couldn’t find the cause of the alert before. Read on for how to find them.
These checks are also handled by the Customer Experience Improvement Program (VMware CEIP). If you are a typical business (not at high risk from cyber-attack), the CEIP program is highly recommended. If you are at risk from cyber-attack, there are ways to secure the CEIP connection so you can still use it.
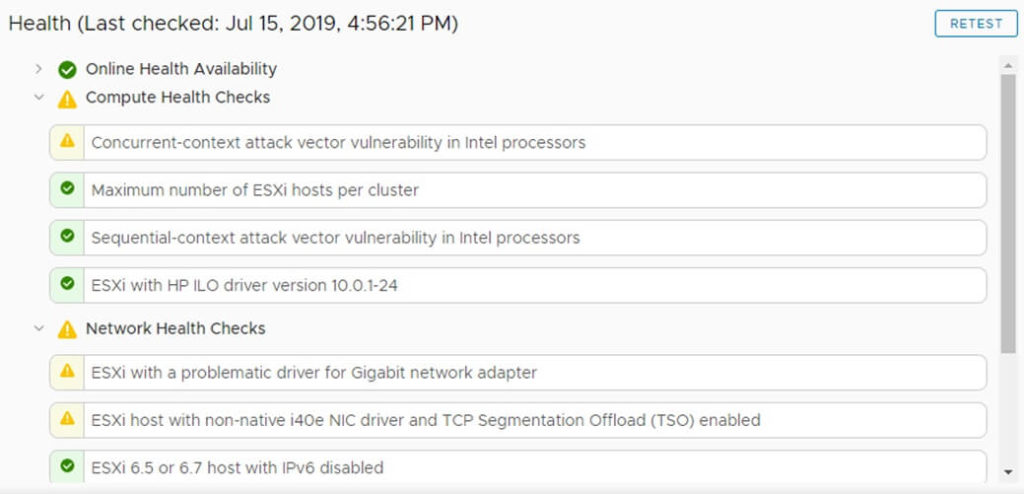
How to troubleshoot the cause of vSphere Health detected new issue in VMware 6.7
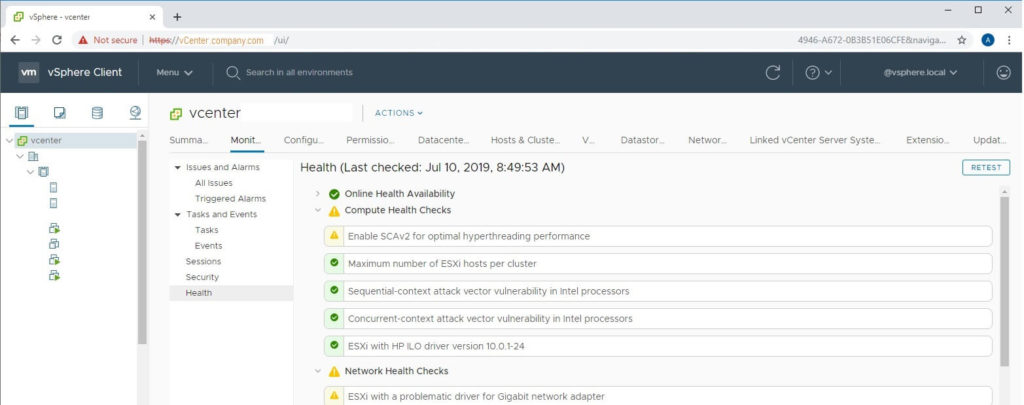
Using the instructions above, open your HTML5 vSphere client by navigating to https://vcenter.company.com/ui
- Select your vCenter object in Hosts & Clusters view. (This is the top level object in your tree)
- Click the Monitor button from the middle menu.
- Click the Health button from the middle-middle menu.
- Identify warnings that have yellow exclamation marks next to them. These are causing your health alarm.
- You can click each item to view information about them. If you select the Info tab for that problem, you will see a button for “Ask VMware” which gives additional help.
- Click the RETEST button on the top-right of the window to see if the issue still exists.
How do I enable CEIP for VMware?
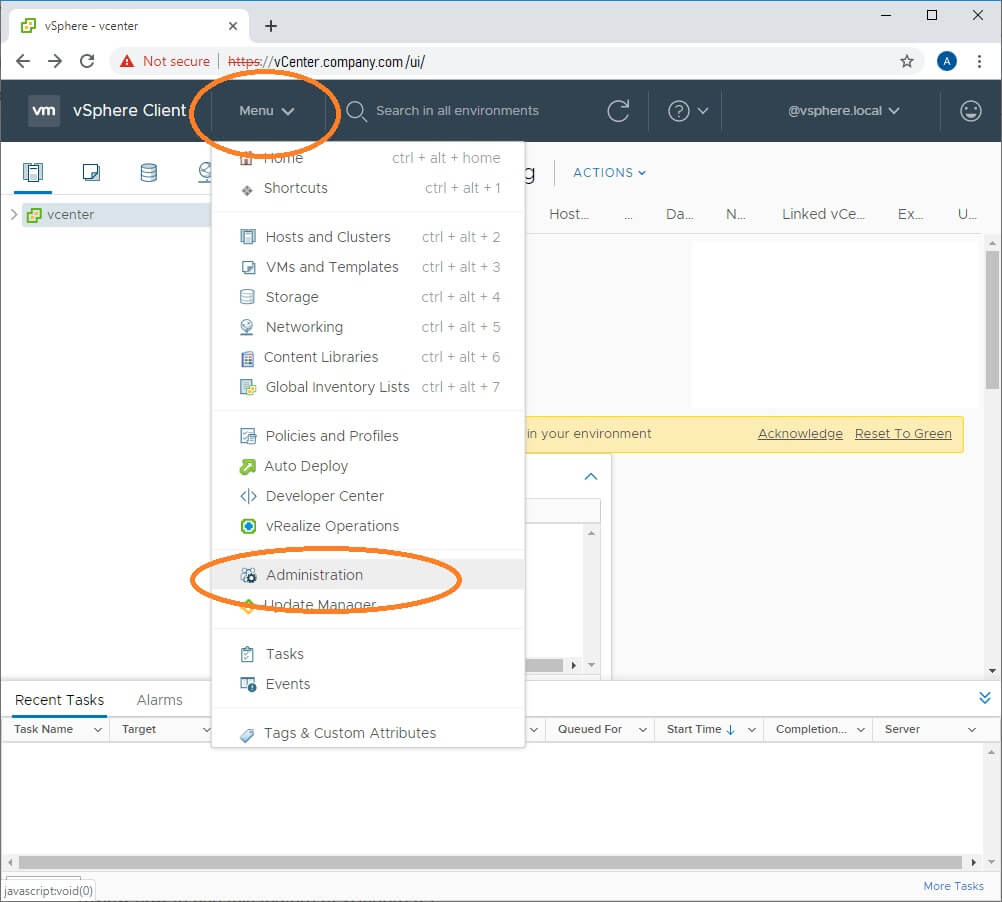
- From the vSphere HTML5 Client, click the Menu drop-down button
- Navigate to Deployment > Customer Experience Improvement Program
- Click Join…
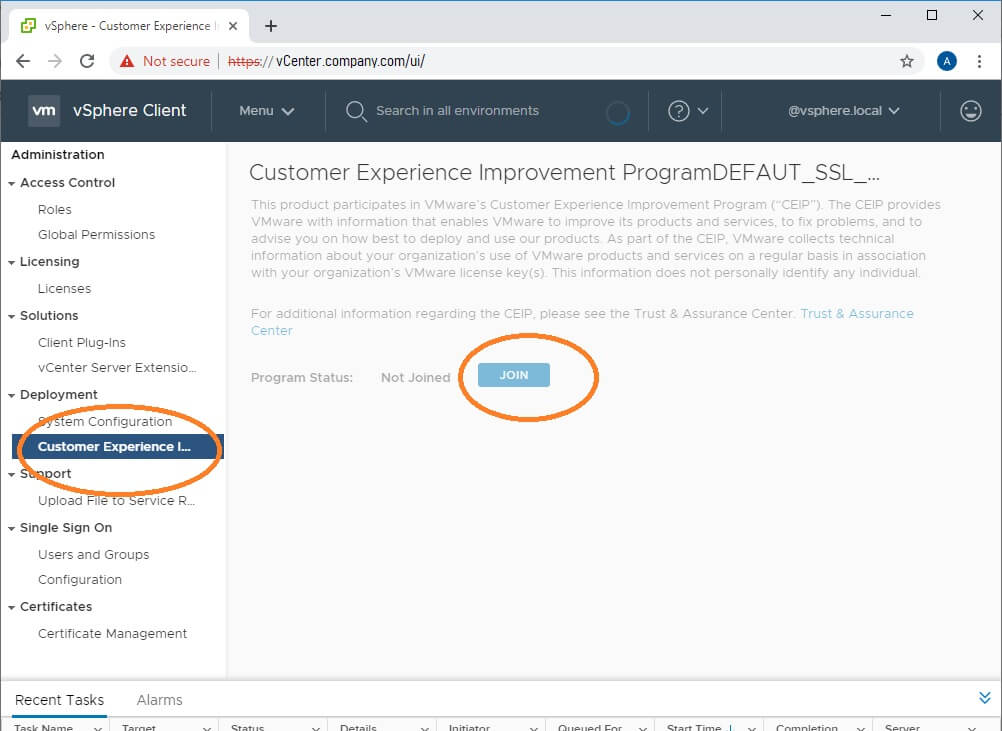
This VMware blog has a nice video of how to click through and enable CEIP if you are having trouble.
How do I fix “Enable SCAv2 for optimal hyperthreading performance”?
This VMware paper describes the issue at great length.
My summary:
This is a continuation of the SPECTRE/MELTDOWN or “L1 Terminal Fault” issue that you’ve heard about.
WARNING: VMware default settings are for highest performance. If you make changes to increase security against SPECTRE / MELTDOWN, your performance may be impacted significantly! In other words, if your virtual environment is using more than 20% CPU at any given time, you should probably NOT enable these changes without a lot of research.
You probably have already applied the fix for previous versions of vSphere. The fix was to edit Advanced System Settings for each host and change the value of VMkernel.Boot.hyperthreadingMitigation = true
In 6.7 Update 2 and later, VMware added VMkernel.Boot.hyperthreadingMitigationIntraVM which defaults to true.
To enable SCAv2, you would verify that VMkernel.Boot.hyperthreadingMitigation = true and change the VMkernel.Boot.hyperthreadingMitigationIntraVM = false and reboot each host.
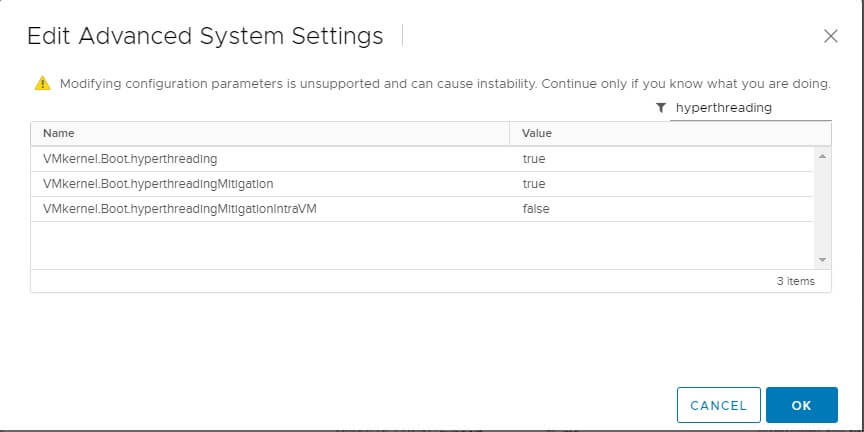
This setting can be reached by opening vSphere Client website (https://vcenter.company.com/ui) then select Hosts & Clusters view, then select a host. Click the Configure tab and select Advanced System Settings from the middle menu. Repeat for each host.
How do I fix “ESXi with a problematic driver for Gigabit network adapter”?
Follow the Ask VMware link on the alert to find specific information about your problematic network card.
It will open a VMware KB article and probably recommend installing an updated driver.
To update to a new driver, here are the basic steps… please use caution and common sense!
- Download the VIB file from VMware
- While you are at it, download the README and review it. If it has instructions, follow those.
- If it is in a .zip format, unzip it and find the .vib file
- Move your VMs to a different host if possible.
- Put your ESXi host into maintenance mode (this procedure could cause impact to any running VMs)
- Back up your ESXi host configuration if you still have any VMs on it (in other words, you can’t afford to rebuild it if something goes wrong).
- Start SSH service in your host > Configuration > Security Profile menu.
- Using WinSCP or another reliable SCP client, connect to your host using IP and root / (root password)
- Navigate to the /tmp/ directory and upload the VIB file to that directory.
- Using Putty or another reliable SSH / console client, connect to your host using IP and root / (root password)
- If your VIB doesn’t say “offline bundle”, type esxcli software vib update -v \tmp\NameOfVIBFile.vib
- If your VIB says “offline bundle”, type esxcli software vib update -d \tmp\NameOfVIBFile-offline_bundle.vib
- Read the results.
- If the the result says “Reboot required: true” , then type reboot (this will reboot your host)
- Make sure to test your host with a non-critical VM before moving important VMs to it.
How do I fix “Concurrent-context attack vector vulnerability in Intel processors”?
This error is referring to the “L1 Terminal Fault” which is widely known as SPECTRE / MELTDOWN.
Basically, there is a flaw in all Intel Processors (at least as of late 2018) which allows processes running in the operating system to observe what the CPU is doing with other processes. This is a critical vulnerability for cloud hosts or any servers that allow untrusted users to access them.
L1 Terminal Fault a major concern for cloud hosting companies, not on-premises companies
For example, if you have an account on AWS, your virtual servers are running on the same physical hardware as other people’s virtual servers. If this vulnerability isn’t mitigated, then you could potentially write code to steal data from the other customers, or vice-versa.
To my knowledge, the vulnerability cannot be exploited without running a process on the system, and most of the people who run processes on servers have no need to snoop on the CPU. In other words, if all the other admins on your server work at your company, you should be fine.
What is the fix?
For now, while the physical processors have this flaw, the fix is to logically reduce the hyper-threading capability of Intel CPUs so they can’t be snooped on. This removes 5-20% of the performance capacity of the CPU.
If your VMware environment isn’t really using the CPU (peak CPU on your hosts is less than 30%), go ahead and implement the fix!
If your servers ARE using the CPU intensively (peak CPU is greater than 30%), then think hard before making a change.
To implement this fix, edit Advanced System Settings for each host and change the value of VMkernel.Boot.hyperthreadingMitigation = true , then reboot the host. Since you are already at 6.7 Update 2, your health alarm will probably change to “Enable SCAv2 for optimal hyperthreading performance” which is addressed a few sections above this one.
What if I don’t want to fix concurrent context?
Some environments cannot afford to lose the CPU performance. For example, I have a client that runs a lab environment with extremely high processing requirements. The hosts are running 70%+ CPU constantly.
So how can you remove the vSphere health warning about concurrent-context attack vector?
At this time, there is no way to disable the warning without changing the settings. I’m monitoring this thread on the topic: https://communities.vmware.com/thread/609376
How do I fix “External Platform Services Controller” deprecated?
Check our other article about this recent (July 2020) issue, which seems to be a false positive.
Event: “Alarm ‘vSphere Health detected new issues in your environment’ on Datacenters changed from Green to Yellow
Even on healthy vCenters, you will see this event appear about once a week. In my environments it lasts for about one hour (green to yellow, then yellow to green). It doesn’t appear to be an actual issue.
Selfish plug time – Need help?
I am a consultant in the Maryland/DC area in the USA. My specialties are Windows migrations (to 2016 and to Office 365 / Azure), VMware migrations, Netapp and SAN, and high availability / disaster recovery planning. If you would like help with your complex project, training, or would like a architectural review to improve your availability, please reach out! More information and contact can be found on the About page. – Amira Armond

August 15, 2019 @ 9:27 am
Thanks for the guide
April 14, 2020 @ 3:19 pm
Hello Amira.
Thank you very much for your helpful blog.
Recently (April 2020) I got the same warning:
vSphere Health detected new issues in your environment
The cause in “skyline help” was:
ESXi host with problematic Broadcom FCoE driver.
pointing to vmware kb article about driver update:
ESXi host Crashed with PSOD caused by brcmfcoe driver referencing __lpfc_sli_get_iocbq (67065)
https://kb.vmware.com/s/article/67065
However i opt to ignore this warning, as i dont have an FCoE device on my server (HPE Proliant Gen10)
Thanks again anyway
Yizhar